已投稿到 脑机接口社区 版权所有。转载自脑机接口社区。禁止其他网站转载
先加载一些必要的头文件
import os
import numpy as np
import mne
import matplotlib.pyplot as plt
plt.rcParams['axes.unicode_minus'] = False #减号
plt.rcParams['font.sans-serif'] = ['SimHei'] #中文字体
plt.rcParams['savefig.dpi'] = 300 #图片像素
plt.rcParams['figure.dpi'] = 300 #分辨率
加载数据
MNE-Python 的数据结构是基于来自Neuromag(脑磁图系统)的FIF文件格式,但是也内置了大量对于其他格式数据的读取函数。MNE-Python 也有各种各样关于公开可获得的数据集接口,来帮助你下载和管理这些数据。
我们将会通过一个加载数据集的例子来开始教程,这个数据集包含来自一个关于听觉和视觉实验的EEG和MEG的数据,数据是通过对被试进行结构化的MRI(磁共振成像)扫描获得的。mne.datasets.sample.data_path函数在数据集没有在指定位置被找到的情况下会自动下载数据集,并且返回目录路径。注意到为了使得教程能够流畅的跑通,我们采用了滤波和降采样后版本的数据,但是样本数据集中也包含了没有滤波的数据,你可以在本地运行的时候进行替换。
sample_data_folder = mne.datasets.sample.data_path()
sample_data_raw_file = os.path.join(sample_data_folder, 'MEG', 'sample',
'sample_audvis_filt-0-40_raw.fif')
raw = mne.io.read_raw_fif(sample_data_raw_file)
Opening raw data file /home/zhkgo/mne_data/MNE-sample-data/MEG/sample/sample_audvis_filt-0-40_raw.fif...
Read a total of 4 projection items:
PCA-v1 (1 x 102) idle
PCA-v2 (1 x 102) idle
PCA-v3 (1 x 102) idle
Average EEG reference (1 x 60) idle
Range : 6450 ... 48149 = 42.956 ... 320.665 secs
Ready.
默认情况下,read_raw_fif函数会打印一些关于它加载的数据集的信息。例如,这次它告诉我们数据集中有四个“投影项”以及记录的数据,时长等信息。这些是SSP投影计算得到的,用于去除来自MEG信号的环境噪声,并且增加了一个平均参考通道。除了在加载数据集时显示信息外,还可以通过打印原始对象来查看数据集基本一些信息,通过打印该对象的info属性可以获取更多信息。info的数据结构中包含了通道位置,已经采用过的滤波器,投影等等信息。
值得注意的是chs条目,它表示MNE-Python 检测到了不同的传感器类型(也就是输入数据包含了来自多种传感器的数据),要注意对这些数据进行适当的处理。如果想要知道更多信息,可以看Info的类定义。
print(raw)
print(raw.info)
<Raw | sample_audvis_filt-0-40_raw.fif, 376 x 41700 (277.7 s), ~3.7 MB, data not loaded>
<Info | 15 non-empty values
bads: 2 items (MEG 2443, EEG 053)
ch_names: MEG 0113, MEG 0112, MEG 0111, MEG 0122, MEG 0123, MEG 0121, MEG ...
chs: 204 GRAD, 102 MAG, 9 STIM, 60 EEG, 1 EOG
custom_ref_applied: False
dev_head_t: MEG device -> head transform
dig: 146 items (3 Cardinal, 4 HPI, 61 EEG, 78 Extra)
file_id: 4 items (dict)
highpass: 0.1 Hz
hpi_meas: 1 item (list)
hpi_results: 1 item (list)
lowpass: 40.0 Hz
meas_date: 2002-12-03 19:01:10 UTC
meas_id: 4 items (dict)
nchan: 376
projs: PCA-v1: off, PCA-v2: off, PCA-v3: off, Average EEG reference: off
sfreq: 150.2 Hz
>
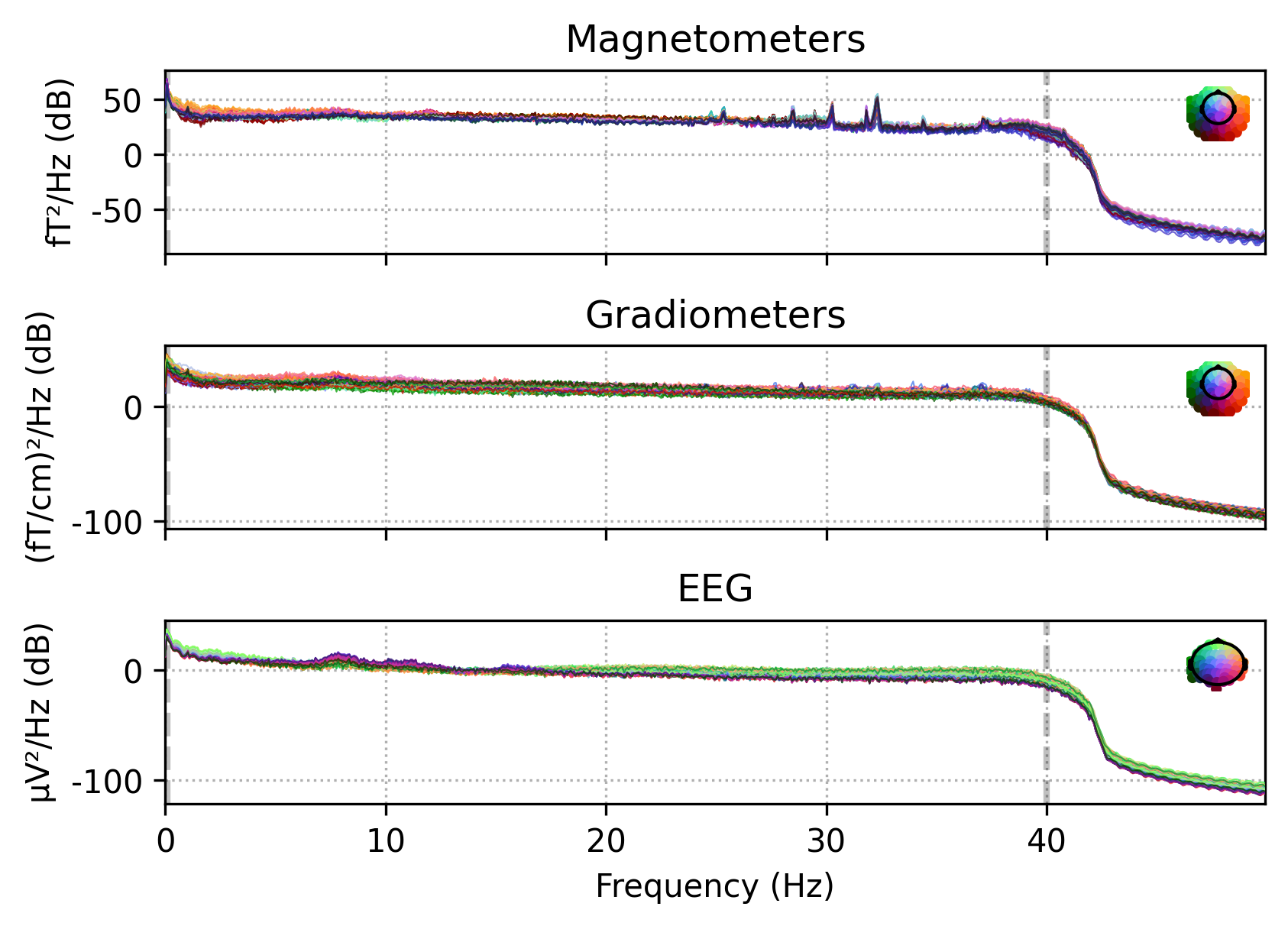
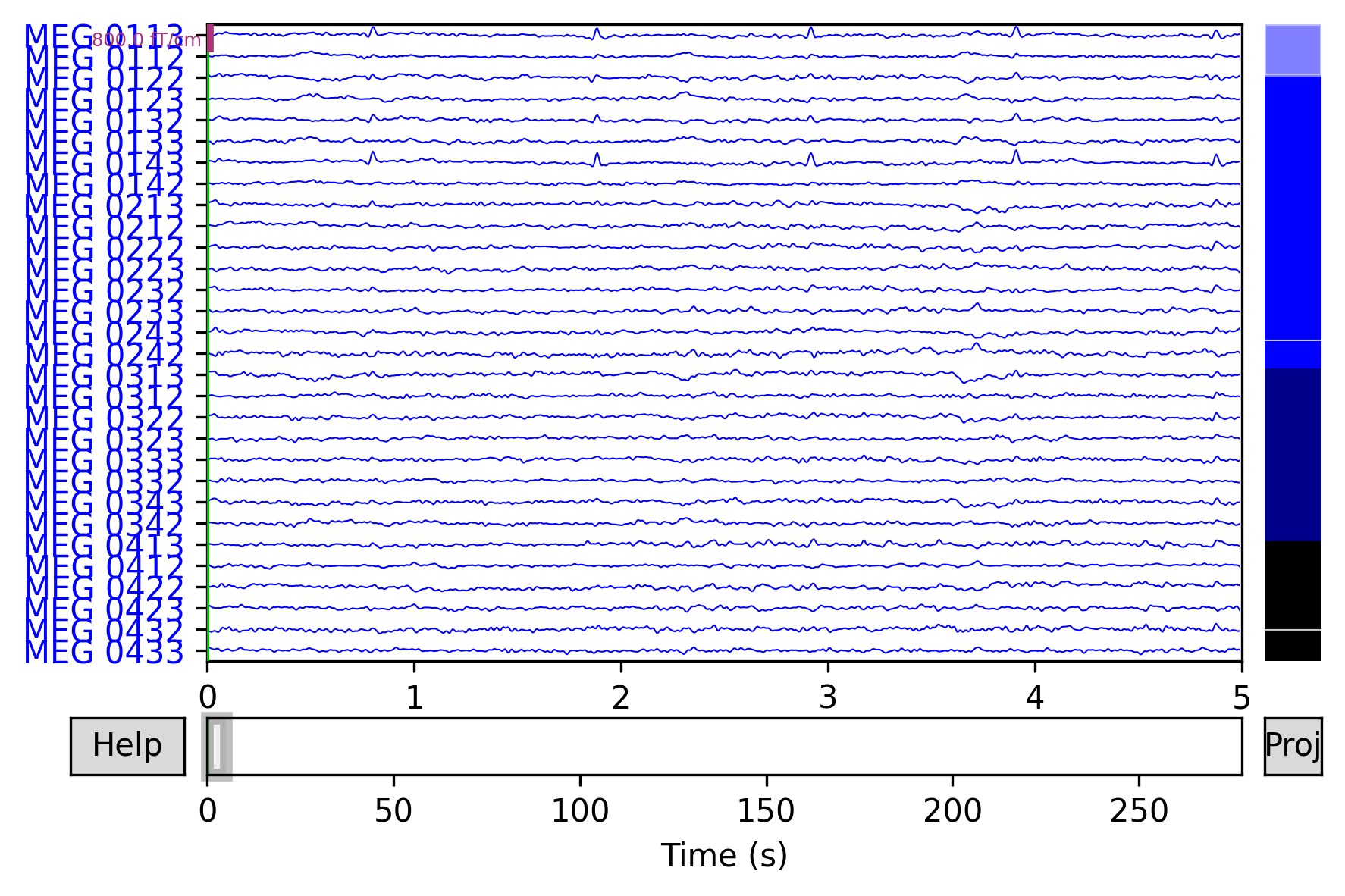
Raw对象有内置的画图函数。在这里,我们通过plot_psd这个函数展示了来自不同传感器数据的功率谱密度图,并且采用plot函数画出了脑电数据的轨迹。在PSD图中,我们只画了50HZ以下的频率(因为我们的数据时已经经过了40HZ的低通滤波)。在交互式Python绘画中(就是能弹出绘图窗口的),绘图是交互式的,并且允许滚动,缩放,标记不良的通道,以及注释等等。
raw.plot_psd(fmax=50)
_=raw.plot(duration=5, n_channels=30)
Effective window size : 13.639 (s)
Effective window size : 13.639 (s)
Effective window size : 13.639 (s)
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
预处理
MNE-Python 支持多种多样的预处理方法和技术(麦克斯韦滤波,信号空间投影(SSP),独立成分分析,滤波,降采样等);具体可以看mne.preprocessing和mne.filter子模块中功能的完整列表。在这里我们将通过独立成分分析(ICA)来清理数据;为了能够简便期间,我们跳过一些步骤。这里可以看一些跳过的步骤
# set up and fit the ICA
ica = mne.preprocessing.ICA(n_components=20, random_state=97, max_iter=800)
ica.fit(raw)
ica.exclude = [1, 2] #这边就是跳过的步骤,关于为什么选择1,2两个成分
ica.plot_properties(raw, picks=ica.exclude)
Fitting ICA to data using 364 channels (please be patient, this may take a while)
Inferring max_pca_components from picks
Selecting by number: 20 components
Fitting ICA took 2.3s.
Using multitaper spectrum estimation with 7 DPSS windows
Not setting metadata
Not setting metadata
138 matching events found
No baseline correction applied
0 projection items activated
0 bad epochs dropped
Not setting metadata
Not setting metadata
138 matching events found
No baseline correction applied
0 projection items activated
0 bad epochs dropped
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
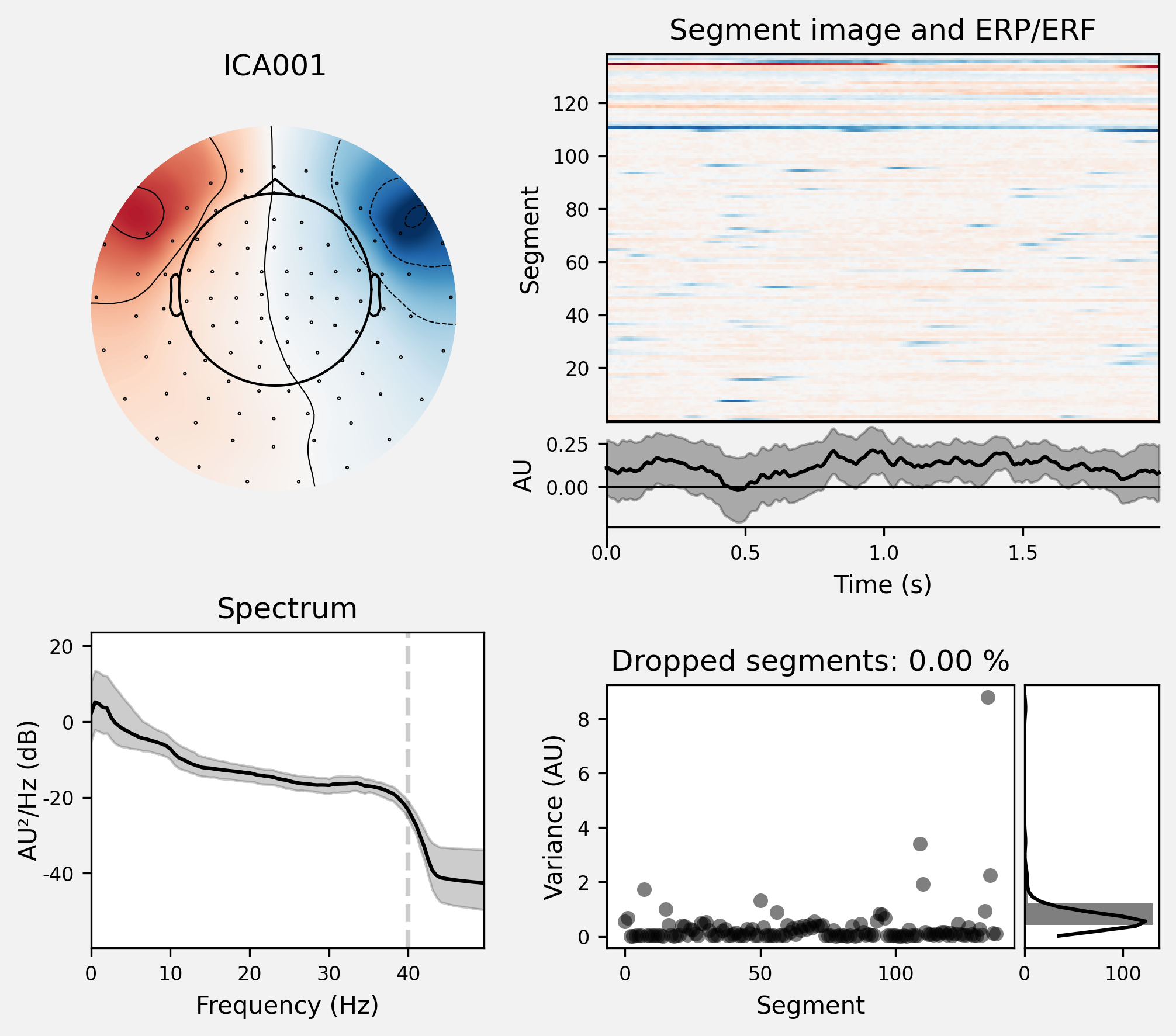
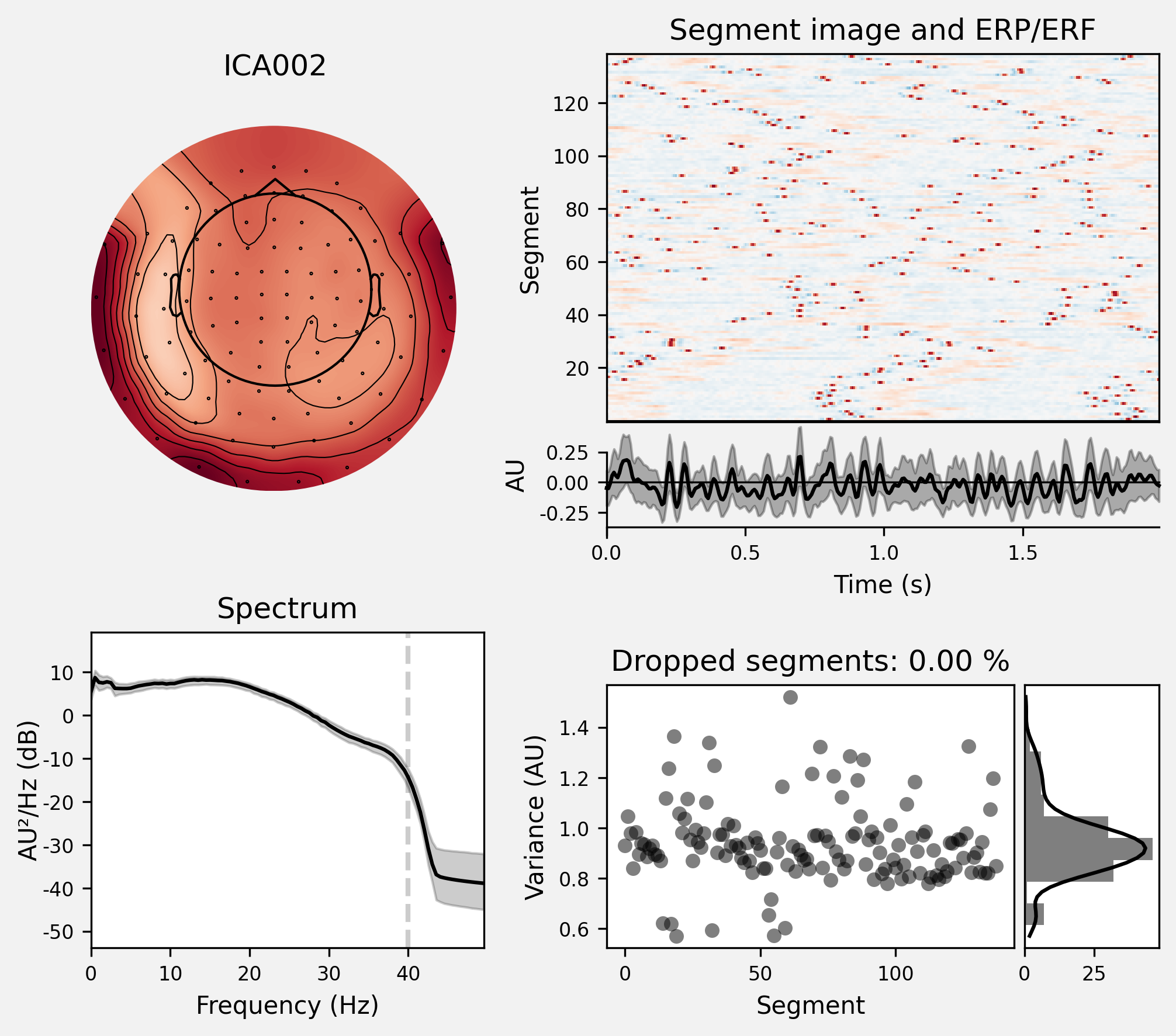
[<Figure size 2100x1800 with 6 Axes>, <Figure size 2100x1800 with 6 Axes>]
在确定要删除哪些成分后,我们将它们作为exclude参数传递,然后将ICA应用于原始信号。 apply方法要求将原始数据加载到内存中(默认情况下,仅根据需要从磁盘读取数据),因此我们使用load_data读取数据之后复制Raw对象,以便我们可以并行比较去除伪迹之前和之后的信号:
orig_raw = raw.copy()
raw.load_data()
ica.apply(raw)
# show some frontal channels to clearly illustrate the artifact removal
chs = ['MEG 0111', 'MEG 0121', 'MEG 0131', 'MEG 0211', 'MEG 0221', 'MEG 0231',
'MEG 0311', 'MEG 0321', 'MEG 0331', 'MEG 1511', 'MEG 1521', 'MEG 1531',
'EEG 001', 'EEG 002', 'EEG 003', 'EEG 004', 'EEG 005', 'EEG 006',
'EEG 007', 'EEG 008']
chan_idxs = [raw.ch_names.index(ch) for ch in chs]
orig_raw.plot(order=chan_idxs, start=12, duration=4)
_=raw.plot(order=chan_idxs, start=12, duration=4)
Reading 0 ... 41699 = 0.000 ... 277.709 secs...
Transforming to ICA space (20 components)
Zeroing out 2 ICA components
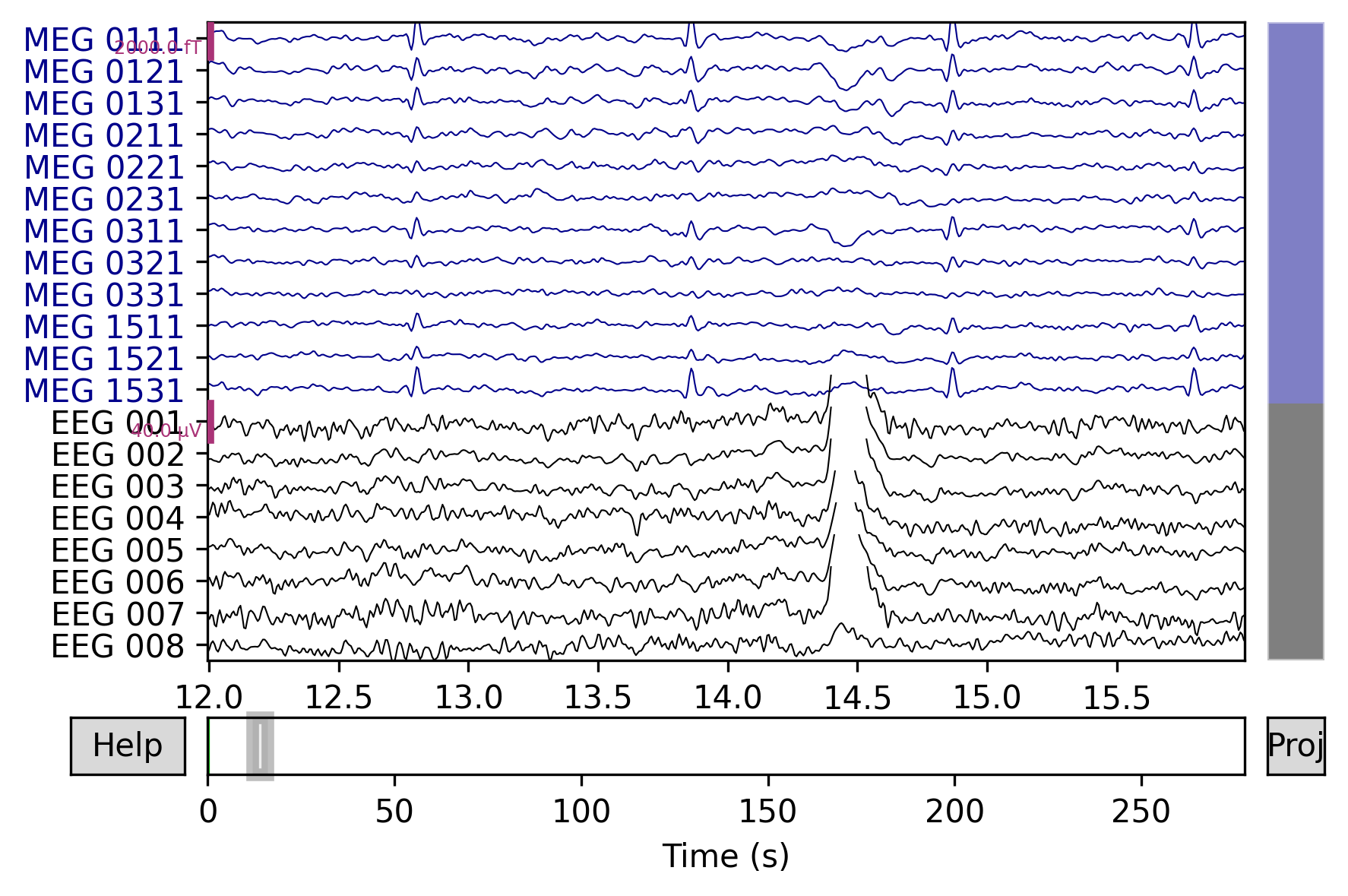
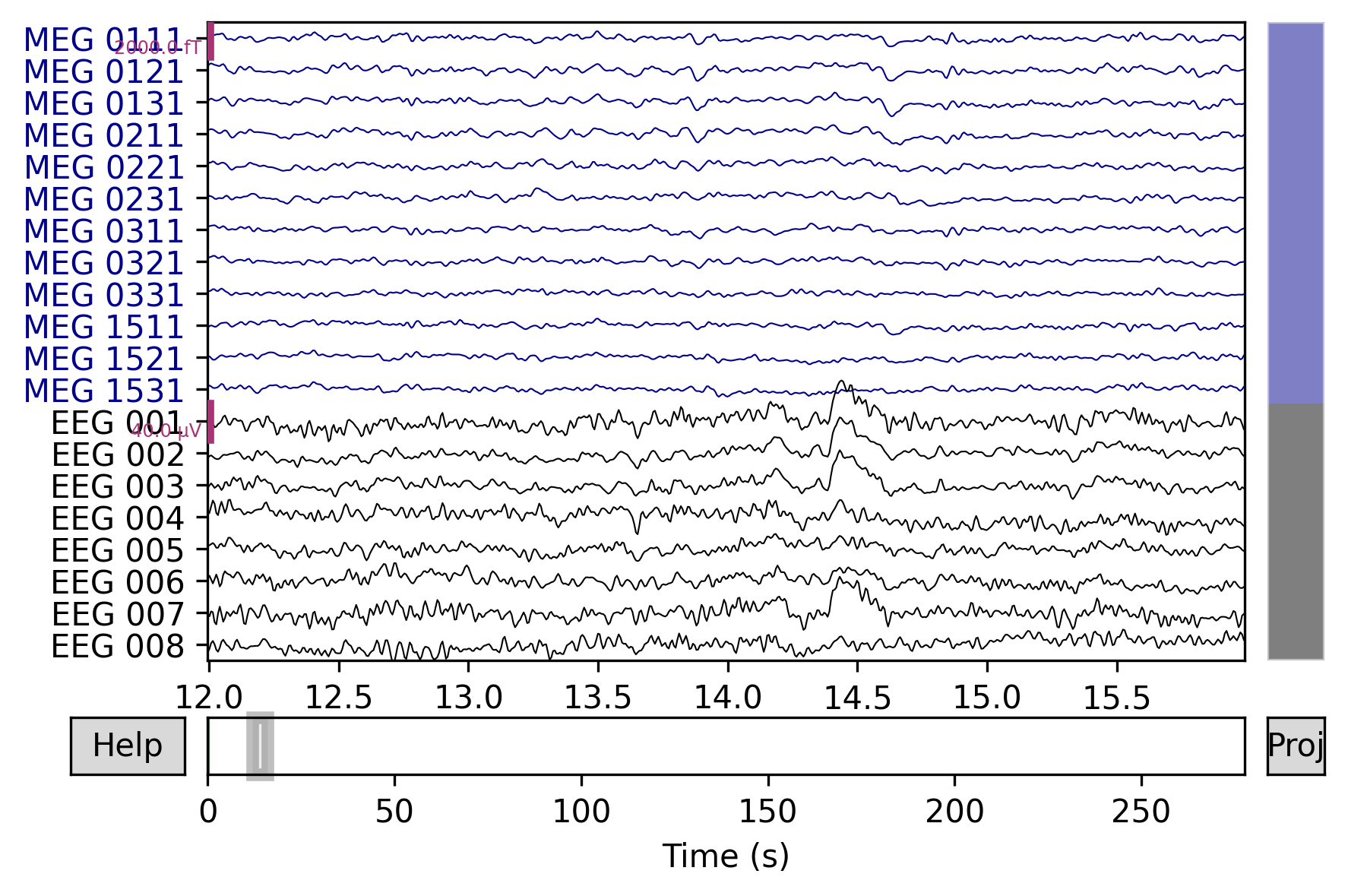
检测标签
样本数据集包括几个STIM通道,这些通道记录了从刺激传递计算机发送的电信号(短暂的DC移位/方波脉冲)。这些脉冲(通常称为“触发”)在此数据集中用于标记实验事件:刺激发作,刺激类型和参与者反应(按下按钮)。各个STIM通道被组合到单个通道中,以使该通道上的电压电平可以明确地解码为特定事件类型。 在较旧的Neuromag系统(例如用于记录样本数据的系统)上,得到的求和通道称为STI 014,因此我们可以将该通道名称传递给mne.find_events函数,以恢复刺激事件的时间和类型。
events = mne.find_events(raw, stim_channel='STI 014')
print(events[:5]) # 显示前五个事件
319 events found
Event IDs: [ 1 2 3 4 5 32]
[[6994 0 2]
[7086 0 3]
[7192 0 1]
[7304 0 4]
[7413 0 2]]
events事件数组是一个普通的3列NumPy数组,第一列为样本编号,最后一列为事件ID; 通常忽略中间列。事件ID通常有对应的事件,在这个样例中其对应关系如下。
| Event ID | Condition |
|---|---|
| 1 | auditory stimulus (tone) to the left ear |
| 2 | auditory stimulus (tone) to the right ear |
| 3 | visual stimulus (checkerboard) to the left visual field |
| 4 | visual stimulus (checkerboard) to the right visual field |
| 5 | smiley face (catch trial) |
| 32 | subject button press |
event_dict = {'auditory/left': 1, 'auditory/right': 2, 'visual/left': 3,
'visual/right': 4, 'smiley': 5, 'buttonpress': 32}
从连续数据中提取epochs时,会使用此类事件字典。字典键中的’/‘ 字符允许通过请求部分条件描述符来跨条件合并(即,请求听觉将选择事件ID为1和2的所有时期;请求向左将选择事件ID为1和3的所有时期)。 下面显示了一个示例。 还有一个方便的plot_events函数,用于可视化记录持续时间内的事件分布(以确保事件检测按预期方式工作)。 在这里,我们还将利用Info属性来获取记录的采样频率(因此,我们的x轴将以秒为单位,而不是采样数)。
fig = mne.viz.plot_events(events, event_id=event_dict, sfreq=raw.info['sfreq'],
first_samp=raw.first_samp)
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
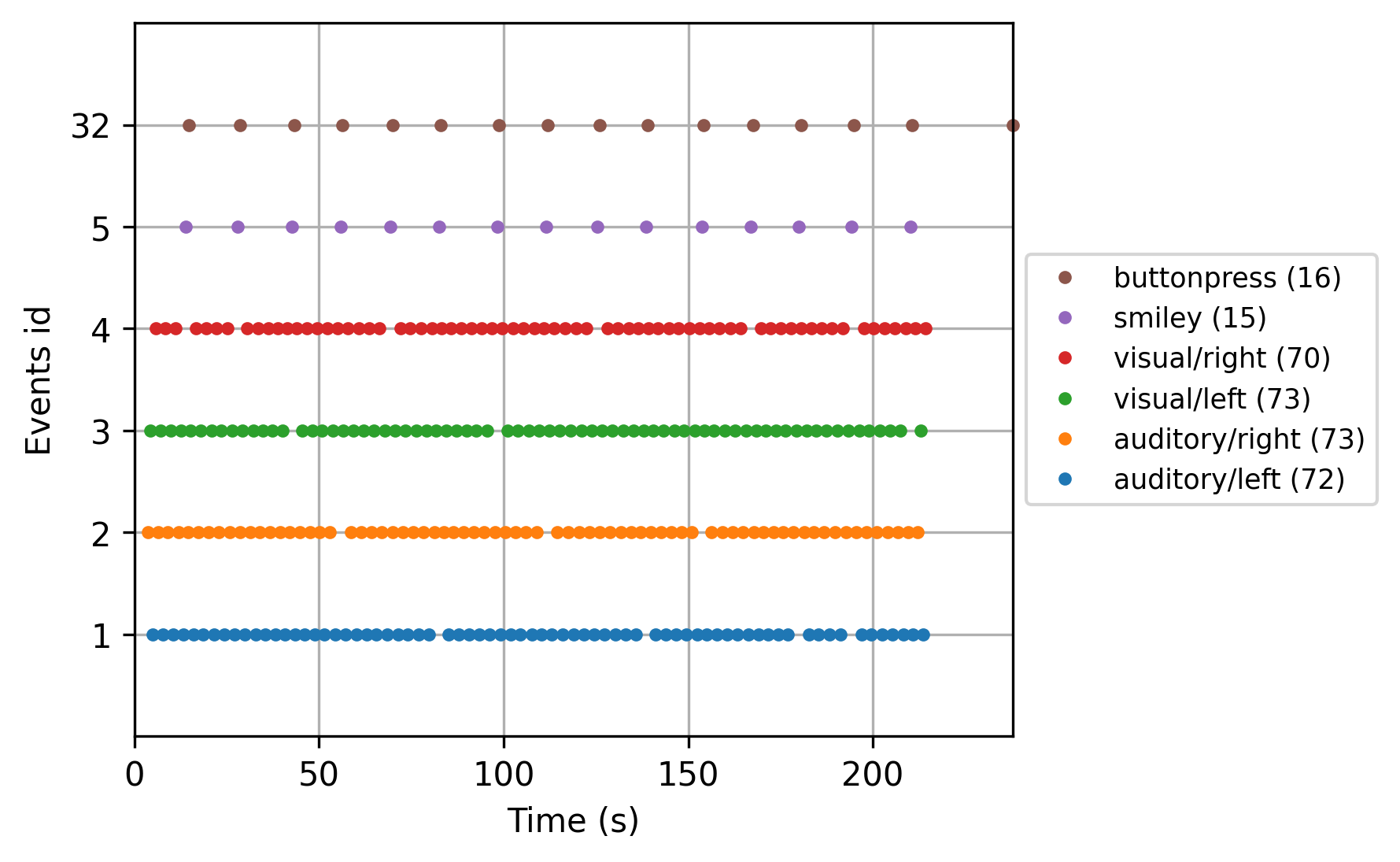
对于与事件无关的范例(例如,对静止状态数据的分析),可以通过使用mne.make_fixed_length_events创建事件。
从连续数据到Epochs(时间段)
Raw对象和events数组是创建Epochs对象所需的基本要求,该对象是我们使用Epochs类构造函数创建的。 在这里,我们还将指定一些数据质量限制:我们将拒绝峰峰值信号幅度超出该通道类型合理限制的任何时期。 这是通过拒绝字典完成的; 您可以为数据中存在的任何渠道类型添加或忽略阈值。 此处给出的值对于此特定数据集是合理的,但可能需要针对不同的硬件或记录条件进行调整。 想要使用更自动化的方法,请考虑使用autoreject软件包。
reject_criteria = dict(mag=4000e-15, # 4000 fT
grad=4000e-13, # 4000 fT/cm
eeg=150e-6, # 150 µV
eog=250e-6) # 250 µV
我们还将事件字典作为event_id参数传递(因此我们可以使用易于合并的事件标签,而不是整数事件ID),并指定tmin和tmax(相对于每个事件开始的时间和结束)。 如上所述,默认情况下,并没有将Raw和Epochs数据加载到内存中(仅在需要时才从磁盘访问它们),但是在这里,我们将使用preload = True参数强制将其加载到内存中,以便我们可以看到结果所使用的拒绝标准:
epochs = mne.Epochs(raw, events, event_id=event_dict, tmin=-0.2, tmax=0.5,
reject=reject_criteria, preload=True)
Not setting metadata
Not setting metadata
319 matching events found
Applying baseline correction (mode: mean)
Created an SSP operator (subspace dimension = 4)
4 projection items activated
Loading data for 319 events and 106 original time points ...
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on MAG : ['MEG 1711']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on MAG : ['MEG 1711']
Rejecting epoch based on EEG : ['EEG 008']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
Rejecting epoch based on EOG : ['EOG 061']
10 bad epochs dropped
接下来,我们将在左右刺激演示中进行汇总,以便我们可以比较听觉和视觉反应。 为避免信号向左或向右偏移,我们将首先使用equalize_event_counts从每个条件中随机采样时间段,以匹配条件中出现的具有最少良好时间段的时间段数。
conds_we_care_about = ['auditory/left', 'auditory/right',
'visual/left', 'visual/right']
epochs.equalize_event_counts(conds_we_care_about) # this operates in-place
aud_epochs = epochs['auditory']
vis_epochs = epochs['visual']
del raw, epochs # free up memory
Dropped 7 epochs: 121, 195, 258, 271, 273, 274, 275
与原始对象一样,Epochs对象也有许多内置的打印方法。一种是plot_image,它将每个epochs显示为图像地图的一行,颜色代表信号大小;图像下方显示了平均诱发响应和传感器位置.
aud_epochs.plot_image(picks=['MEG 1332', 'EEG 021'])
Not setting metadata
Not setting metadata
136 matching events found
No baseline correction applied
0 projection items activated
0 bad epochs dropped
Not setting metadata
Not setting metadata
136 matching events found
No baseline correction applied
0 projection items activated
0 bad epochs dropped
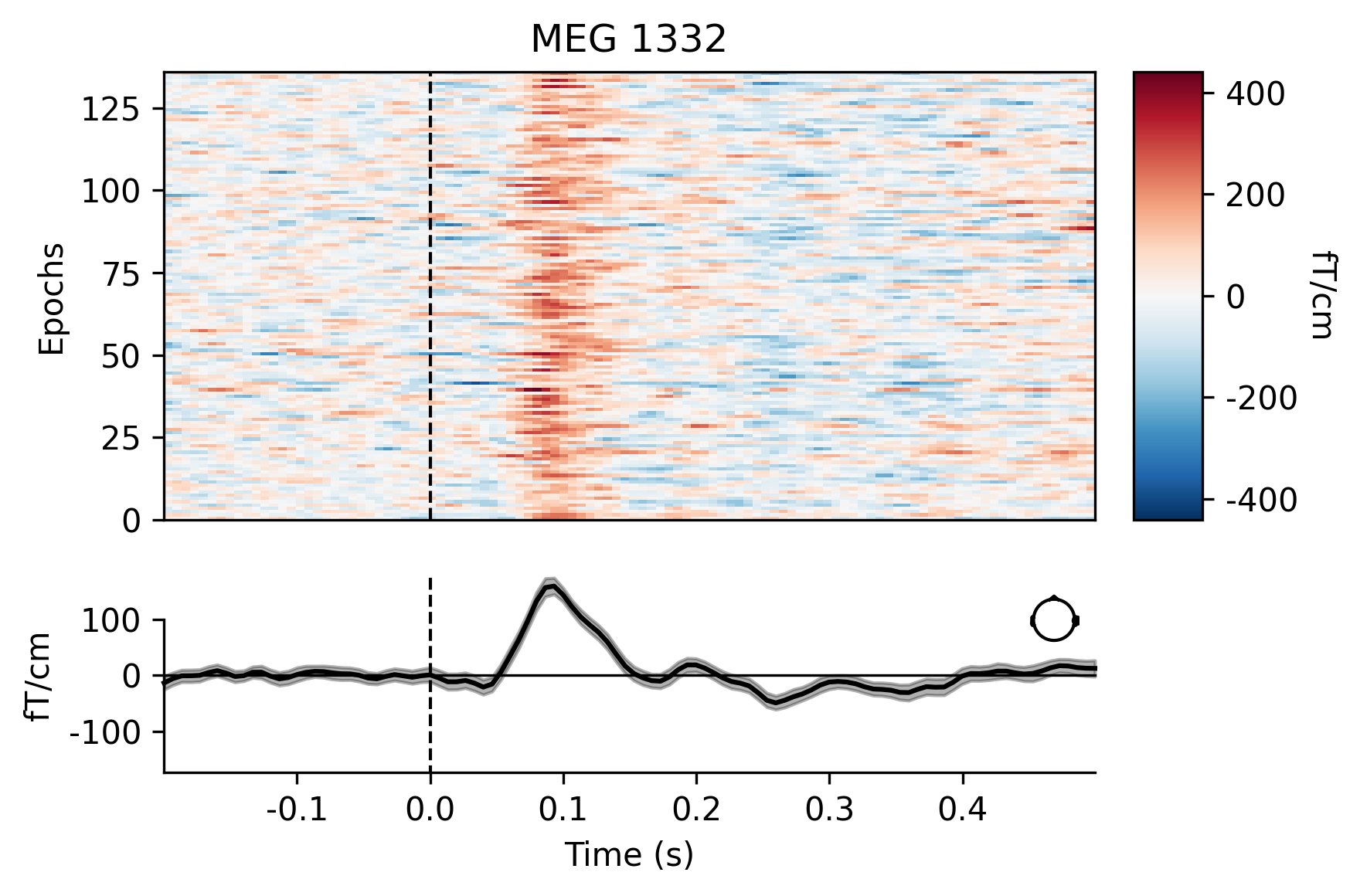
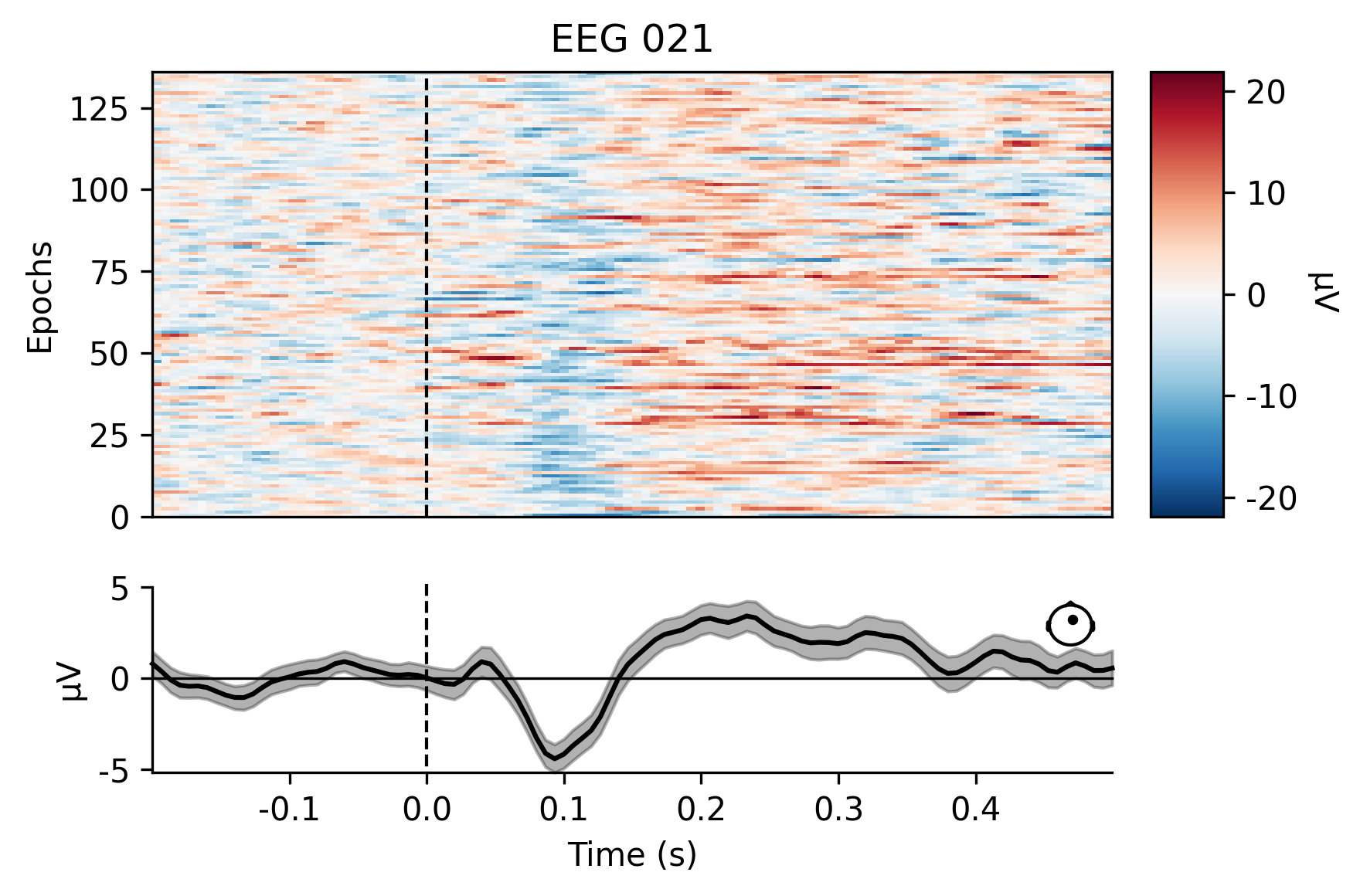
[<Figure size 1800x1200 with 4 Axes>, <Figure size 1800x1200 with 4 Axes>]
注意 Raw和Epochs对象都具有get_data方法,这些方法将基础数据作为NumPy数组返回。 两种方法都有一个picks参数,用于选择要返回的通道。raw.get_data()具有用于限制时域的其他参数。 所得矩阵的原始尺寸为(n_channels,n_times),Epochs为(n_epochs,n_channels,n_times)。
时频分析
mne.time_frequency子模块提供了几种算法的实现,以计算时频表示,功率谱密度和互谱密度。 例如,在这里,我们将使用Morlet小波为听觉时期计算不同频率和时间的感应功率。 在此数据集上,结果并不是特别有用(它仅显示诱发的“听觉N100”响应); 有关具有更丰富频率内容的数据集的更多扩展示例,请参见此处。
frequencies = np.arange(7, 30, 3)
power = mne.time_frequency.tfr_morlet(aud_epochs, n_cycles=2, return_itc=False,
freqs=frequencies, decim=3)
_=power.plot(['MEG 1332'])
Removing projector <Projection | PCA-v1, active : True, n_channels : 102>
Removing projector <Projection | PCA-v2, active : True, n_channels : 102>
Removing projector <Projection | PCA-v3, active : True, n_channels : 102>
Removing projector <Projection | Average EEG reference, active : True, n_channels : 60>
Removing projector <Projection | PCA-v1, active : True, n_channels : 102>
Removing projector <Projection | PCA-v2, active : True, n_channels : 102>
Removing projector <Projection | PCA-v3, active : True, n_channels : 102>
Removing projector <Projection | Average EEG reference, active : True, n_channels : 60>
No baseline correction applied
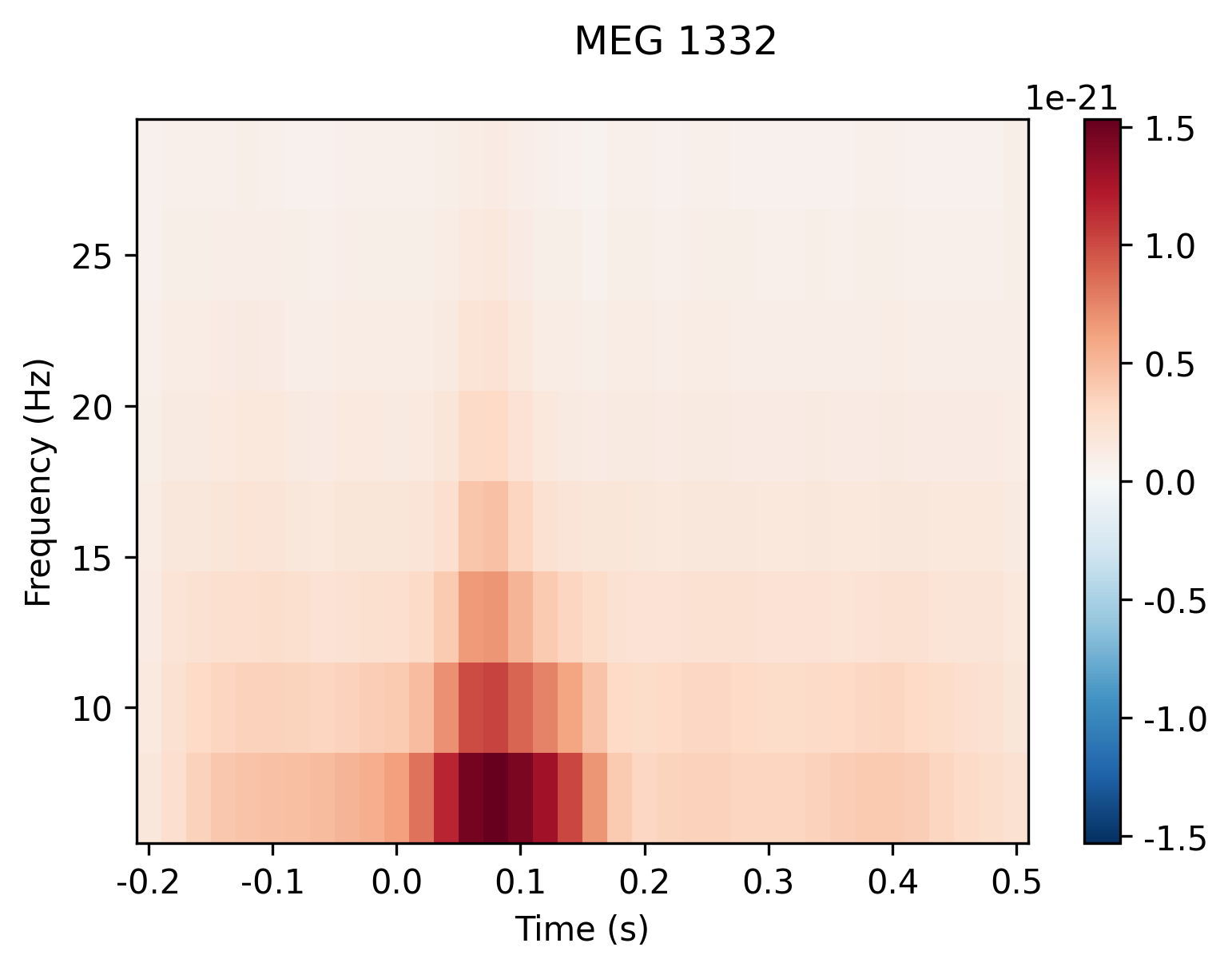
诱发反应
现在,我们已经把ud_epochs和vis_epochs区分开了。可以通过将每个条件下的epochs平均在一起,来估计对听觉与视觉刺激的诱发反应。这就像在Epochs对象上调用average方法,然后使用mne.viz模块中的函数来比较两个Evoked对象的每种传感器类型的全局场功率一样简单.
aud_evoked = aud_epochs.average()
vis_evoked = vis_epochs.average()
mne.viz.plot_compare_evokeds(dict(auditory=aud_evoked, visual=vis_evoked),
legend='upper left', show_sensors='upper right')
Multiple channel types selected, returning one figure per type.
combining channels using "gfp"
combining channels using "gfp"
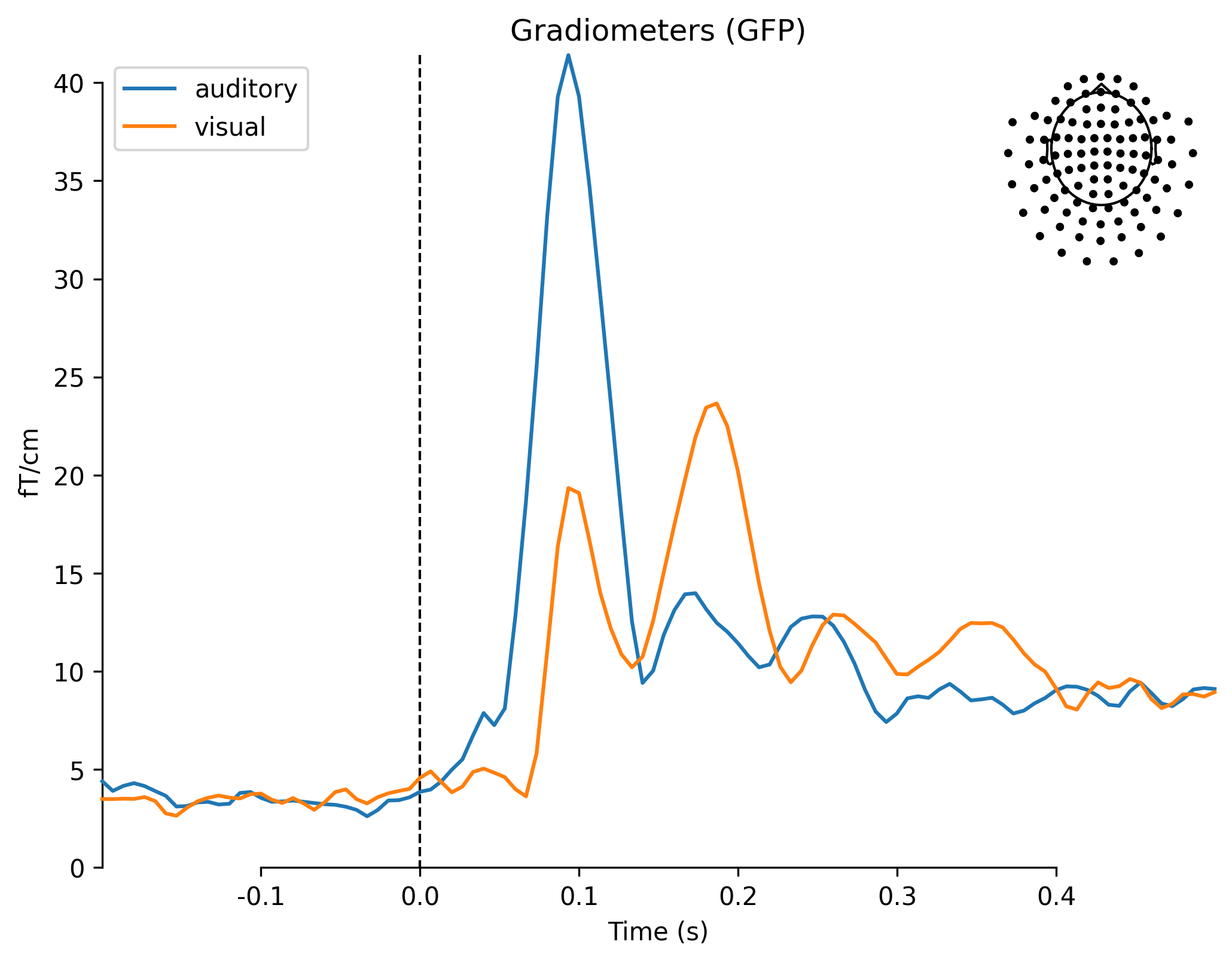
combining channels using "gfp"
combining channels using "gfp"
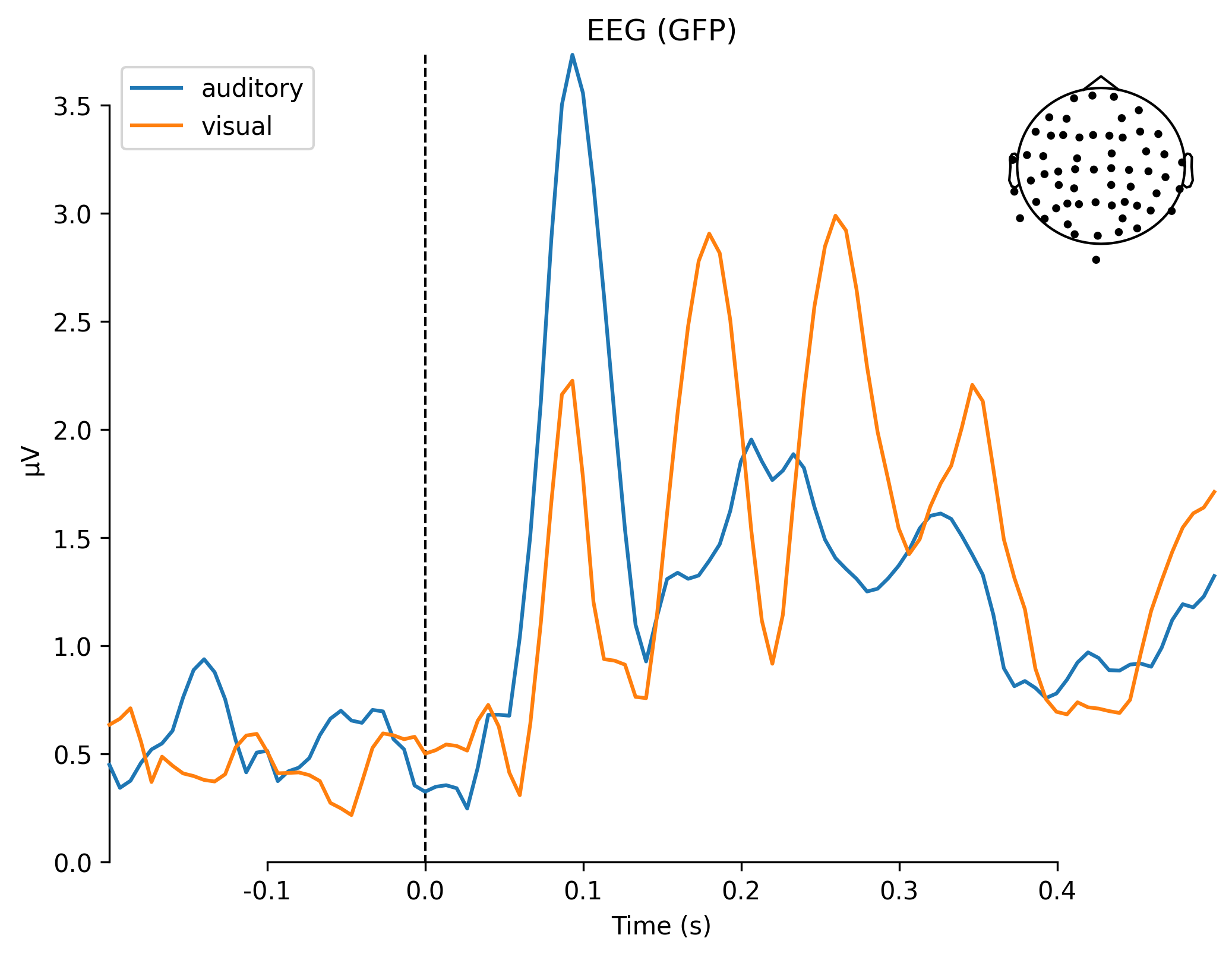
combining channels using "gfp"
combining channels using "gfp"
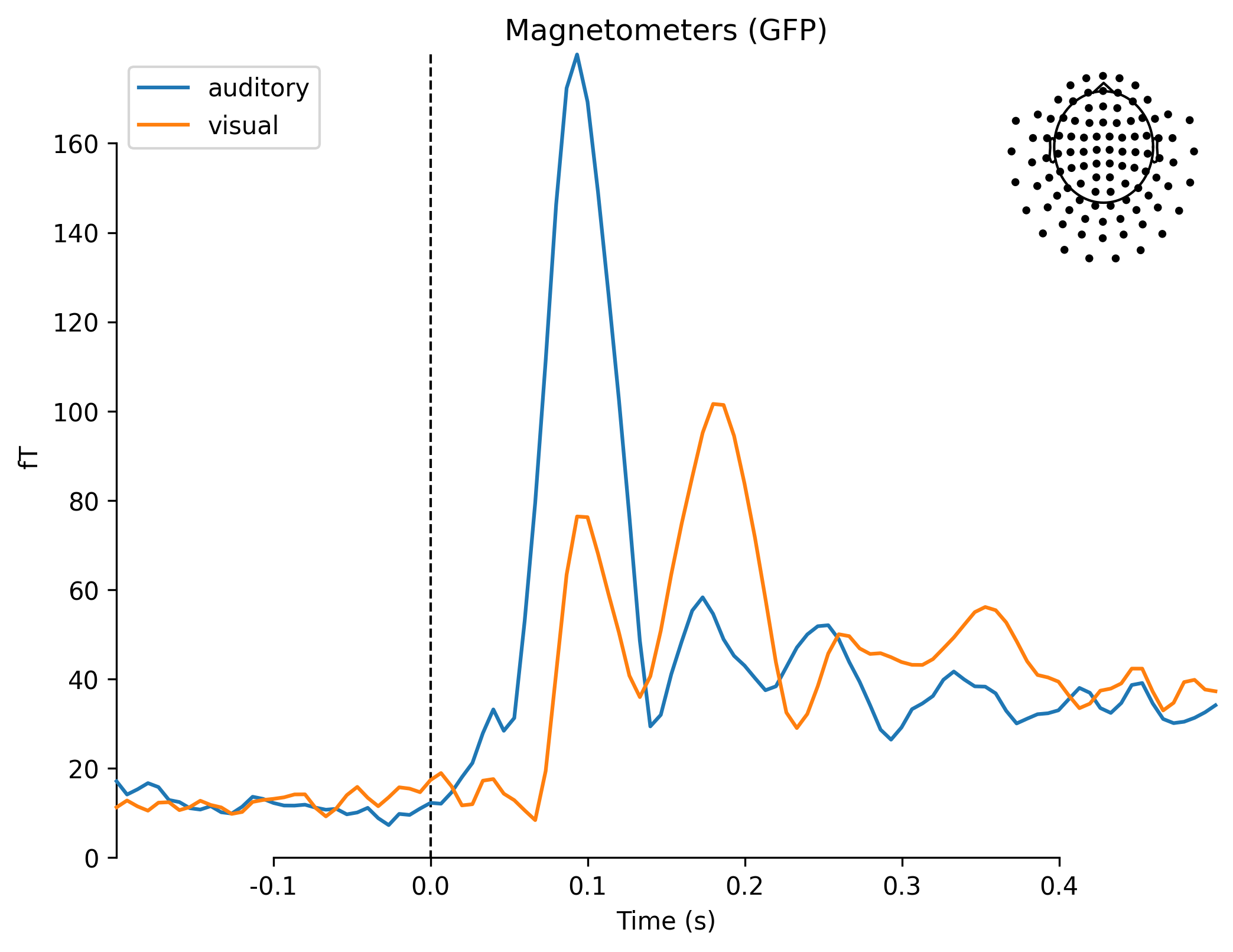
[<Figure size 2400x1800 with 2 Axes>,
<Figure size 2400x1800 with 2 Axes>,
<Figure size 2400x1800 with 2 Axes>]
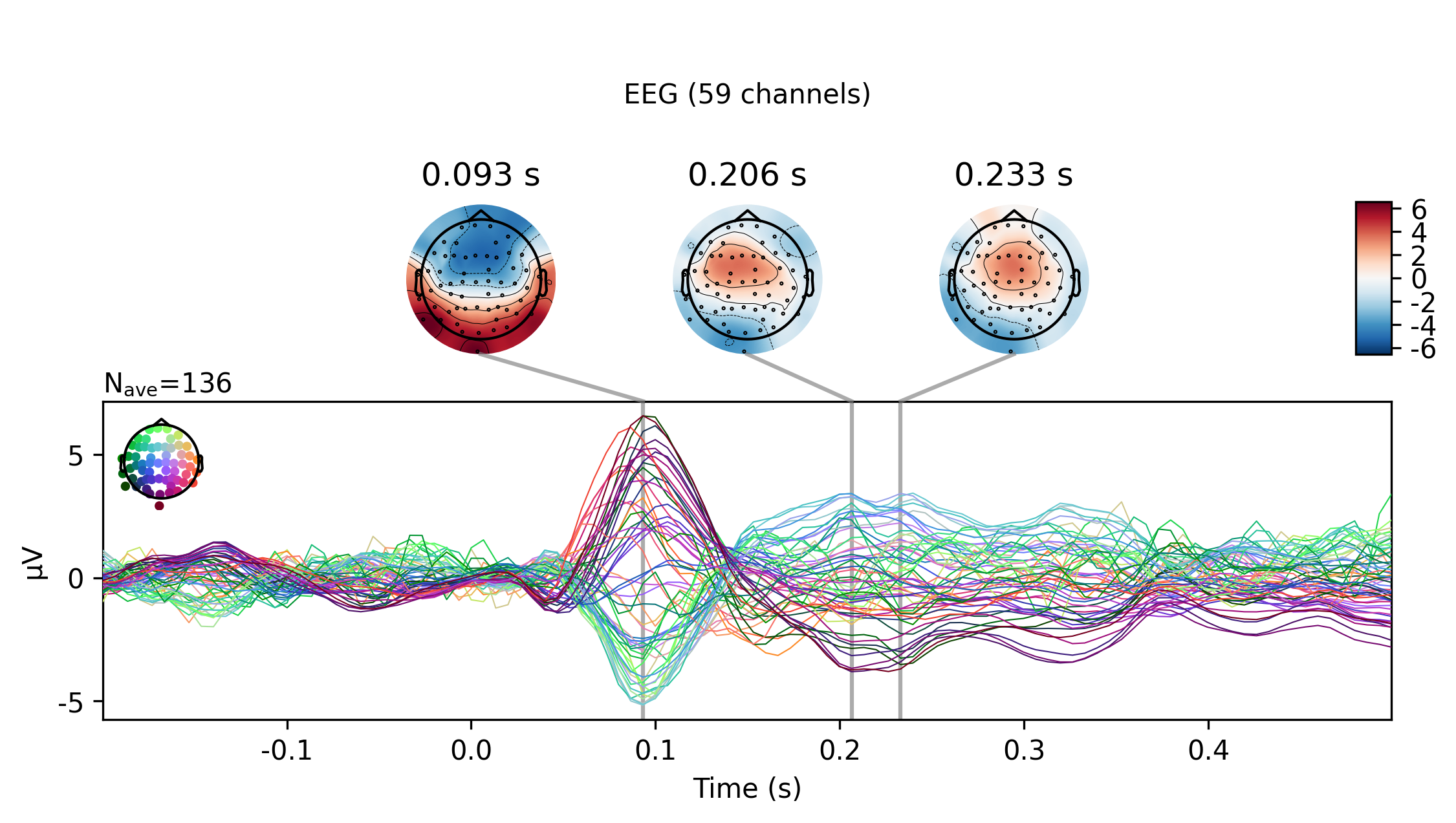
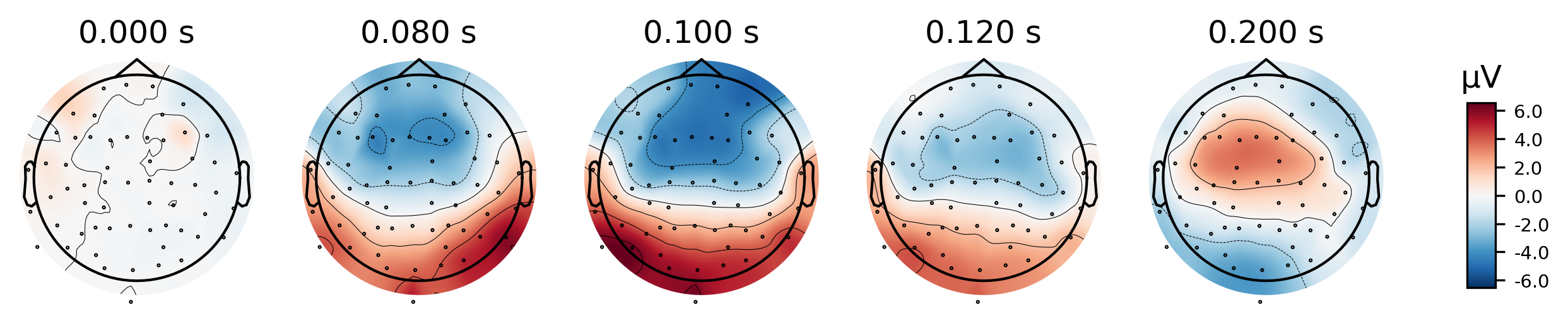
我们还可以使用诸如plot_joint或plot_topomap之类的其他绘图方法来获得每个被唤起对象的更详细视图。 在这里,我们将仅检查EEG通道,并在背侧额电极上看到经典的听觉诱发N100-P200模式,然后在任意其他时间绘制脑地形图。
aud_evoked.plot_joint(picks='eeg')
_=aud_evoked.plot_topomap(times=[0., 0.08, 0.1, 0.12, 0.2], ch_type='eeg')
Projections have already been applied. Setting proj attribute to True.
Removing projector <Projection | PCA-v1, active : True, n_channels : 102>
Removing projector <Projection | PCA-v2, active : True, n_channels : 102>
Removing projector <Projection | PCA-v3, active : True, n_channels : 102>
Removing projector <Projection | PCA-v1, active : True, n_channels : 102>
Removing projector <Projection | PCA-v2, active : True, n_channels : 102>
Removing projector <Projection | PCA-v3, active : True, n_channels : 102>
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
使用mne.combine_evoked函数,还可以将evokes对象组合在一起以显示条件之间的对比。 通过传递权重= [1,-1]可以产生一个简单的差异。 然后,我们使用plot_topo在每个传感器上绘制差异波:
evoked_diff = mne.combine_evoked([aud_evoked, vis_evoked], weights=[1, -1])
_=evoked_diff.pick_types(meg='mag').plot_topo(color='r', legend=False)
Removing projector <Projection | Average EEG reference, active : True, n_channels : 60>


