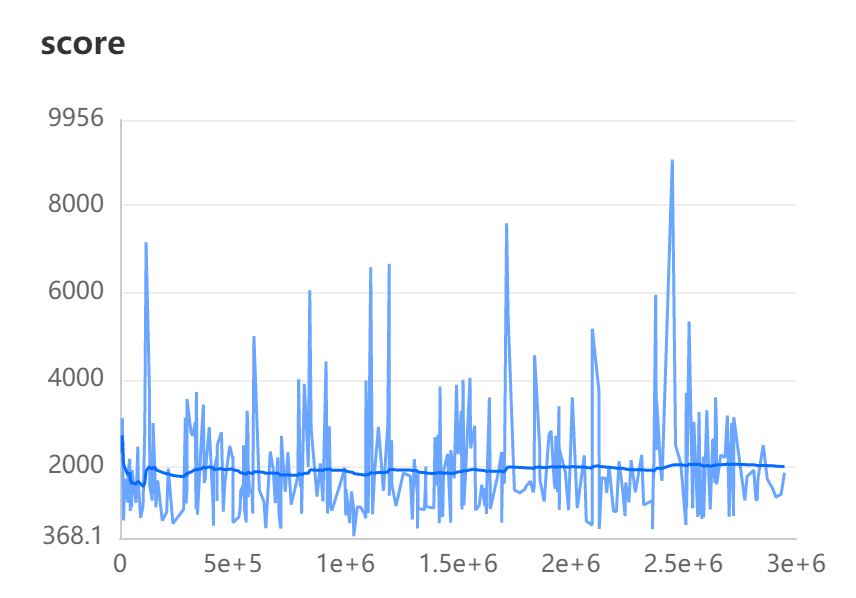
暑假空闲时间比较多,就来试试炼丹。这个AI我尝试设计了好多次,总是会有这样那样的问题,现在总算有了相对稳定的效果。
动作的设计
俄罗斯方块最原始的动作是五个,分别是不动,下落,旋转,左移,右移。为了能够使得他直击目标,我们对动作进行了组合,即从新方块出来到彻底落下为一个动作。俄罗斯方块有10列,那么方块可以从0-9列下降,为了方便设计动作,我设置了冗余,也就是说把所有方块做相同的处理,即可以不动,或者向左五次,向右五次,共11个平移动作。还有一层就是旋转动作,可以旋转0-3次。这样一组合最终的动作空间共有44个动作。
奖励函数的设计
对于奖励函数,我这边按照自己的想法设计了一下。主要基于以下几个指标。
- 方块落下后方块最高的高度
- 方块落下后消除的行数
- 方块落下后有多少个空洞
- 方块落下后的不平整度(具体而言是指列高度差值的绝对值之和)
我们直接取消除行数命名为L。针对高度,空洞,不平整度,我们对动作的评分需要消除前置影响,即前面积累的差的局面对这个动作的评分无影响(或者说影响较小),所以采用差值,即当前高度减去前一局面的高度命名为H,当前空洞减去前一局面的空洞数做D,当前局面不平整度减去前一局面不平整度做B。
经过精心的设计(玄学调参),我选择了以下的参数作为权值。
| 影响因子 | 权值W |
|---|---|
| H | 30 |
| L | 50 |
| D | 8 |
| B | 2 |
Double DQN的设计
网络模块
这边采用了深度神经网络。输入层为216个01像素,其中10X20的像素表示当前的局面,4X4个像素表示下一个方块。最终通过网络输出44个动作的Q值。
import cv2
import os
import matplotlib.pyplot as plt
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph import Conv2D, Pool2D, Linear, BatchNorm
class QNetworks(fluid.dygraph.Layer):
def __init__(self, name_scope, num_classes=1):
super(QNetworks, self).__init__(name_scope)
name_scope = self.full_name()
self.fc1=Linear(input_dim=216,output_dim=1024,act="relu")
self.fc2=Linear(input_dim=1024,output_dim=2048,act="relu")
self.fc3=Linear(input_dim=2048,output_dim=1024,act="relu")
self.fc4=Linear(input_dim=1024,output_dim=num_classes)
# 网络的前向计算过程
def forward(self, x):
x=self.fc1(x)
x=self.fc2(x)
x=fluid.layers.dropout(x,dropout_prob =0.5)
x=self.fc3(x)
x=self.fc4(x)
return x
训练模块
这边衰减设置为0.98,EPSILON从1变化到0.01期间迭代1500000次。作为Double DQN TargetNetWork替换为1000迭代替换一次。
import numpy as np
import random
from collections import deque
import time
from visualdl import LogWriter
class BrainDQN:
# Hyper Parameters:
ACTION = 44
FRAME_PER_ACTION = 1
GAMMA = 0.98 # decay rate of past observations
OBSERVE = 10000. # timesteps to observe before training
EXPLORE = 1500000. # frames over which to anneal epsilon
FINAL_EPSILON = 0.01 # final value of epsilon
INITIAL_EPSILON =1 #starting value of epsilon
REPLAY_MEMORY = 50000 # number of previous transitions to remember
BATCH_SIZE = 128 # size of minibatch
REPLACE_TARGET_FREQ = 1000
def __init__(self):
# init replay memory
self.replayMemory = deque()
# init Q network
self.createTQNetwork()
self.createQNetwork()
# init some parameters
self.timeStep = 0
self.updateTQNetwork()
self.writer=LogWriter(logdir='log/train_loss')
self.epsilon = self.INITIAL_EPSILON
self.opt = fluid.optimizer.Momentum(learning_rate=1e-7, momentum=0.9, parameter_list=self.model.parameters())
#首次运行请注释下面两行
# model_dict, _ = fluid.load_dygraph(self.model.full_name())
# self.model.load_dict(model_dict)
def updateTQNetwork(self):
if self.timeStep % self.REPLACE_TARGET_FREQ == 0:
self.tmodel.load_dict(self.model.state_dict())
def createTQNetwork(self):
self.tmodel=QNetworks("TQNetwork",self.ACTION)
def createQNetwork(self):
self.model=QNetworks("QNetwork",self.ACTION)
# model_dict, _ = fluid.load_dygraph(self.model.full_name())
# self.model.load_dict(model_dict)
def trainQNetwork(self):
# Step 1: obtain random minibatch from replay memory
minibatch = random.sample(self.replayMemory,self.BATCH_SIZE)
state_batch = fluid.dygraph.to_variable(np.array([data[0] for data in minibatch],dtype="float32"))
action_batch = fluid.dygraph.to_variable(np.array([data[1] for data in minibatch],dtype="float32"))
reward_batch = fluid.dygraph.to_variable(np.array([data[2] for data in minibatch],dtype="float32"))
nextState_batch = fluid.dygraph.to_variable(np.array([data[3] for data in minibatch],dtype="float32"))
# Step 2: calculate y
y_batch = []
self.model.eval()
self.tmodel.eval()
QValue_batch = self.model(nextState_batch)
max_action_next = np.argmax(QValue_batch.numpy(), axis=1)
TQValue_batch = self.tmodel(nextState_batch)
TQValue_batch_numpy=TQValue_batch.numpy()
reward_batch_numpy=reward_batch.numpy()
for i in range(0,self.BATCH_SIZE):
terminal = minibatch[i][4]
if terminal:
y_batch.append(reward_batch_numpy[i])
else:
target_Q_value = TQValue_batch_numpy[i, max_action_next[i]]
y_batch.append(reward_batch_numpy[i] + self.GAMMA * target_Q_value)
# print("start train")
self.model.train()
y_batch = fluid.dygraph.to_variable(np.array(y_batch,dtype="float32"))
# print("predict")
QValue=self.model(state_batch)
# print("Qaction")
Q_action=fluid.layers.reduce_sum(fluid.layers.elementwise_mul(QValue,action_batch),dim=1)
# print("cost")
cost=fluid.layers.reduce_mean(fluid.layers.square(y_batch-Q_action))
# print("backward")
cost.backward()
# print("opt")
self.opt.minimize(cost)
# print("clear")
self.model.clear_gradients()
# print("update")
self.updateTQNetwork()
# print("start log")
# save network every 100000 iteration
if self.timeStep % 10000 == 0:
fluid.save_dygraph(self.model.state_dict(),self.model.full_name())
fluid.save_dygraph(self.tmodel.state_dict(),self.tmodel.full_name())
self.writer.add_scalar(tag='cost', step=self.timeStep, value=cost.numpy())
def setPerception(self,nextObservation,action,reward,terminal):
#print(nextObservation.shape)
print("/ REWARD", reward)
newState =nextObservation
self.replayMemory.append((self.currentState,action,reward,newState,terminal))
if len(self.replayMemory) > self.REPLAY_MEMORY:
self.replayMemory.popleft()
if self.timeStep > self.OBSERVE:
# Train the network
self.trainQNetwork()
self.currentState = newState
self.timeStep += 1
def getAction(self):
self.model.eval()
QValue = self.model(fluid.dygraph.to_variable(np.array([self.currentState])))[0].numpy()
# print(type(QValue))
#time.sleep(0.05)
action = np.zeros(self.ACTION)
action_index = 0
if self.timeStep % self.FRAME_PER_ACTION == 0:
if random.random() <= self.epsilon:
action_index = random.randrange(self.ACTION)
action[action_index] = 1
else:
action_index = np.argmax(QValue)
action[action_index] = 1
else:
action[0] = 1 # do nothing
# change episilon
if self.epsilon > self.FINAL_EPSILON and self.timeStep > self.OBSERVE:
self.epsilon -= (self.INITIAL_EPSILON - self.FINAL_EPSILON)/self.EXPLORE
print("TIMESTEP", self.timeStep, \
"/ EPSILON", self.epsilon, "/ ACTION", action_index, \
"/ Q_MAX %e" % np.max(QValue),end='')
return action
def setInitState(self,observation):
self.currentState = observation
运行调用模块
代码在下面不多说了。
import cv2
import sys
sys.path.append("game/")
import tetris_fun_reward as game
import numpy as np
# preprocess raw image to 100*50 gray image
def preprocess(observation):
board = observation[220:420,75:475,:]
nextp = observation[520:600,100:180,:]
xt1 = cv2.cvtColor(cv2.resize(board, (20, 10)), cv2.COLOR_BGR2GRAY)
xt2 = cv2.cvtColor(cv2.resize(nextp, (4, 4)), cv2.COLOR_BGR2GRAY)
xt1 = np.reshape((xt1 != 0) + 0, (-1))
xt2 = np.reshape((xt2 != 0) + 0, (-1))
xt = np.concatenate((xt1, xt2))
return np.array(xt,dtype="float32")
def playGame():
# Step 1: init BrainDQN
brain = BrainDQN()
# Step 2: init Flappy Bird Game
tetris = game.GameState()
# Step 3: play game
# Step 3.1: obtain init state
action0 = np.zeros(brain.ACTION) # do nothing'
action0[0] = 1
observation0, reward0, terminal = tetris.combine_step(action0)
observation0 = preprocess(observation0)
brain.setInitState(observation0)
i=0
# Step 3.2: run the game
while i < brain.EXPLORE*2:
action = brain.getAction()
nextObservation,reward,terminal = tetris.combine_step(action)
nextObservation = preprocess(nextObservation)
brain.setPerception(nextObservation,action,reward,terminal)
i+=1
def main():
playGame()
if __name__ == '__main__':
with fluid.dygraph.guard(fluid.CUDAPlace(0)):
main()
训练结果
跑了几个小时得分的分布如下图。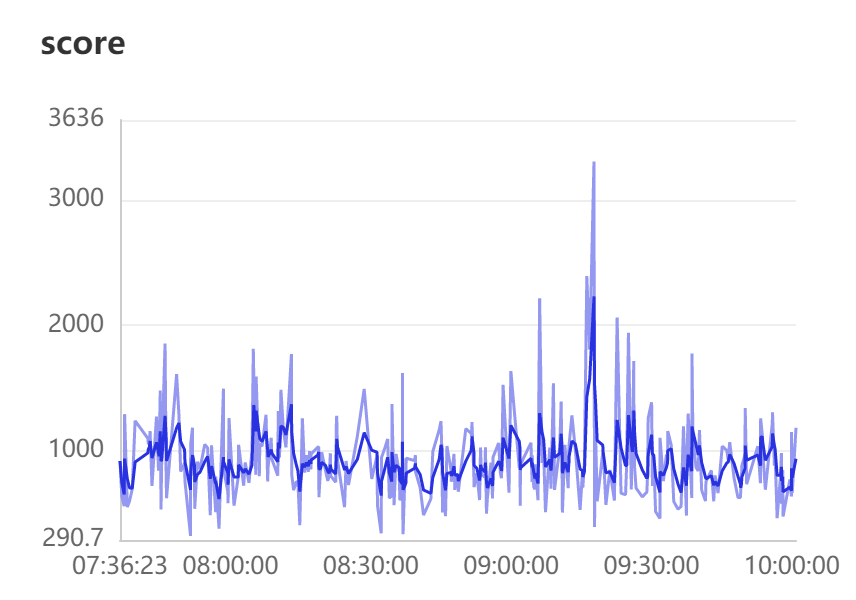
可以看出分数都分布在1000以上,偶尔突破1500算是有不错的效果了。
下面是在本机跑俄罗斯方块AI的效果图。
可以看出这边对于空洞的重视程度还不是特别足,需要更好的设计奖励函数。
补充
发现了一个bug,游戏内部的设定问题,导致组合后的动作有些区域落不到方块,修复了bug之后重新训练得分变得很好。