因为百度的AIStudio平台提供了免费的GPU算力,而且帮我配好了运行环境,只不过需要使用paddlepaddle这个框架,我就打算顺便在学习paddlepaddle的同时完成lintcode上面的刷题任务。
题目描述
题目链接
给出一张猫或狗的图片,识别出这是猫还是狗。
这种识别具有很重要的意义,比如:
Web服务为了进行保护,会防止一些计算机进行恶意访问或信息爬取,进而设立一些验证问题,这些验证问题对于人来说很容易做,但是对于计算机这很困难。这样的方法称为CAPTCHA(完全自动公开的图灵测试)或HIP(人类交互证明)。 HIP有很多用处,例如减少垃圾邮件,防止暴力破解密码等。
题目分析
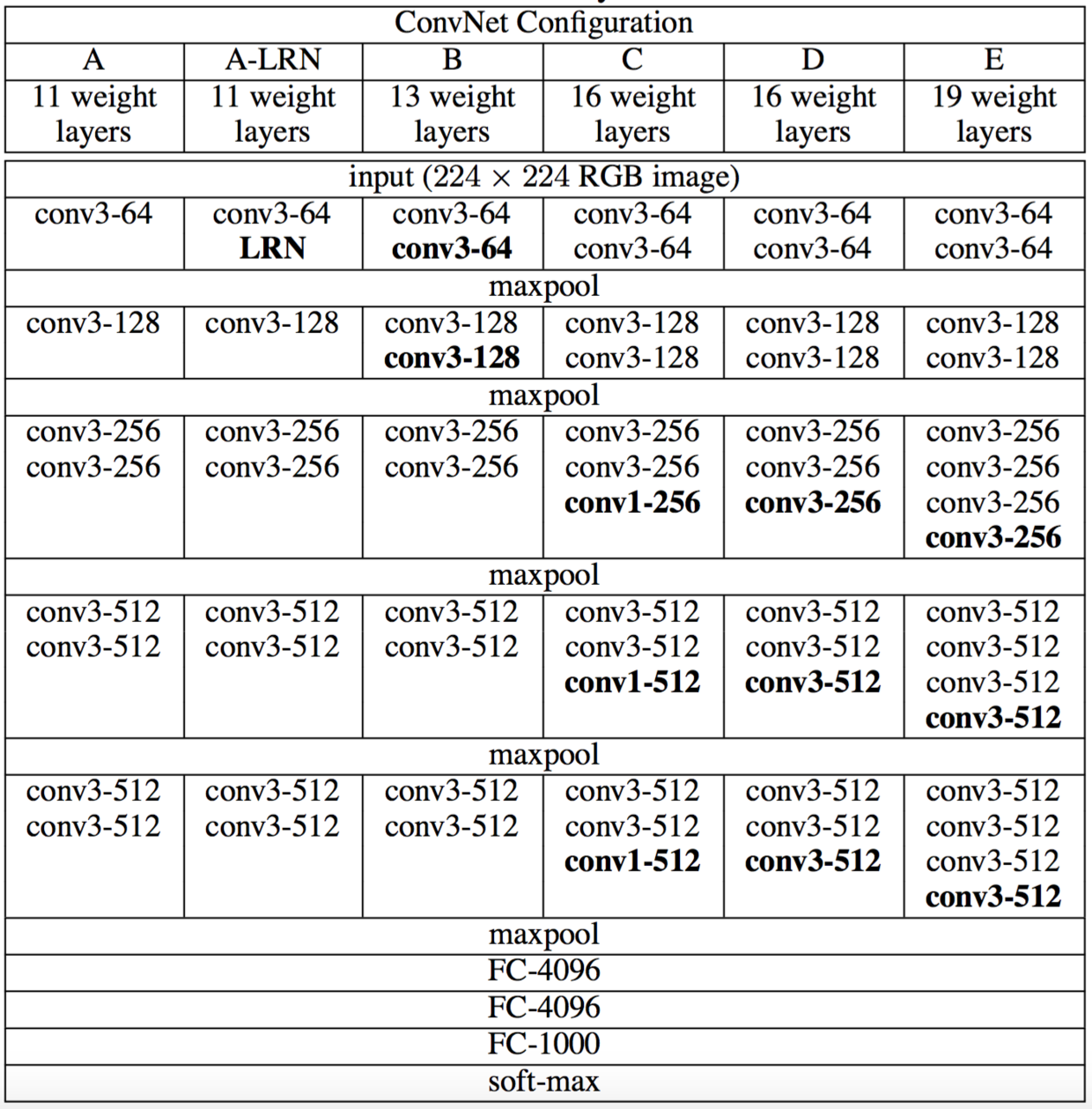
很明显是一个简单的二分类任务,但是如果要分的好还是需要有一定的小技巧。这里主要用到了经典的VGG19模型。
“VGG”代表了牛津大学的Oxford Visual Geometry Group。VGG模型采用模块化的方式将网络堆叠到了19层以增强性能。(图片来自网络)
数据预处理
首先把图片读进来,然后用cv2将图片统一尺寸到300X300,并且用pickle重新打包存储方便后面读取使用。如果是cat也就是c开头的文件就打标签0,否则就是狗,打标签1。
import pickle
def preprocess(img):
return cv2.resize(img,(300,300))
def picReader(path="work/train"):
for name in os.listdir(path):
fullpath=os.path.join(path,name)
img=cv2.imread(fullpath)
img=preprocess(img)
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
assert img.shape==(300,300,3)
label=1
if name[0]=='c':
label=0
yield img,label
ls=list(picReader())
f=open("traindata","wb")
arr=np.array(ls)
np.random.shuffle(arr)
pickle.dump(arr,f)
f.close()
数据分批读取模块编写
三个模块,分别是训练数据,测试数据,以及全部数据。训练数据测试数据是用来看模型的拟合状况的。全部数据是为了在确认模型无误之后拿所有的有标签数据来训练模型以此提高模型的分类能力。
def trainDataReader(filename="traindata"):
f=open(filename,"rb")
arr=pickle.load(f)
for i in range(int(len(arr)*0.9)):
img,label=arr[i]
yield img,label
def testDataReader(filename="traindata"):
f=open(filename,"rb")
arr=pickle.load(f)
for i in range(int(len(arr)*0.9),len(arr)):
img,label=arr[i]
yield img,label
def allDataReader(filename="traindata"):
f=open(filename,"rb")
arr=pickle.load(f)
for i in range(len(arr)):
img,label=arr[i]
yield img,label
VggNet定义
这里加了BN层以此来抑制模型的过拟合。
from visualdl import LogWriter
import re
import os
import shutil
import paddle.fluid as fluid
import numpy as np
import pickle
import paddle
# VGG加BN层抑制过拟合
class VGG_BN(fluid.dygraph.Layer):
def __init__(self, name_scope, num_classes=1, layer=13):
super(VGG_BN, self).__init__(name_scope)
name_scope = self.full_name()
self.layer = layer
self.pool = Pool2D(pool_size=2, pool_stride=2)
self.bn64 = BatchNorm(64)
self.bn128 = BatchNorm(128)
self.bn256 = BatchNorm(256)
self.bn512 = BatchNorm(512)
self.conv1 = Conv2D(3, 64, 3, padding=1, act='relu')
self.conv2 = Conv2D(64, 64, 3, padding=1, act='relu')
self.conv3 = Conv2D(64, 128, 3, padding=1, act='relu')
self.conv4 = Conv2D(128, 128, 3, padding=1, act='relu')
self.conv5 = Conv2D(128, 256, 3, padding=1, act='relu')
self.conv6 = Conv2D(256, 256, 3, padding=1, act='relu')
self.conv7 = Conv2D(256, 256, 3, padding=1, act='relu')
self.conv8 = Conv2D(256, 256, 3, padding=1, act='relu')
self.conv9 = Conv2D(256, 512, 3, padding=1, act='relu')
self.conv10 = Conv2D(512, 512, 3, padding=1, act='relu')
self.conv11 = Conv2D(512, 512, 3, padding=1, act='relu')
self.conv12 = Conv2D(512, 512, 3, padding=1, act='relu')
self.conv13 = Conv2D(512, 512, 3, padding=1, act='relu')
self.conv14 = Conv2D(512, 512, 3, padding=1, act='relu')
self.conv15 = Conv2D(512, 512, 3, padding=1, act='relu')
self.conv16 = Conv2D(512, 512, 3, padding=1, act='relu')
self.fc1 = Linear(input_dim=512 *9 * 9, output_dim=4096, act='relu')
self.fc2 = Linear(input_dim=4096, output_dim=4096, act='relu')
self.fc3 = Linear(input_dim=4096, output_dim=num_classes)
# 网络的前向计算过程
def forward(self, x):
x = self.conv1(x)
# x = self.bn64(x)
x = self.conv2(x)
# x = self.bn64(x)
x = self.pool(x)
x = self.conv3(x)
# x = self.bn128(x)
x = self.conv4(x)
x = self.bn128(x)
x = self.pool(x)
x = self.conv5(x)
# x = self.bn256(x)
x = self.conv6(x)
# x = self.bn256(x)
if self.layer >= 16:
x = self.conv7(x)
# x = self.bn256(x)
if self.layer >= 19:
x = self.conv8(x)
# x = self.bn256(x)
x = self.pool(x)
x = self.conv9(x)
x = self.bn512(x)
x = self.conv10(x)
# x = self.bn512(x)
if self.layer >= 16:
x = self.conv11(x)
# x = self.bn512(x)
if self.layer >= 19:
x = self.conv12(x)
# x = self.bn512(x)
x = self.pool(x)
x = self.conv13(x)
# x = self.bn512(x)
x = self.conv14(x)
# x = self.bn512(x)
if self.layer >= 16:
x = self.conv15(x)
# x = self.bn512(x)
if self.layer >= 19:
x = self.conv16(x)
# x = self.bn512(x)
x = self.pool(x)
x = fluid.layers.reshape(x, [-1, 512 *9*9])
x = self.fc1(x)
x = fluid.layers.dropout(x,dropout_prob=0.5)
x = self.fc2(x)
x = fluid.layers.dropout(x,dropout_prob=0.5)
x = self.fc3(x)
return x
进行训练
这里的迭代轮数选了30,batch_size用了50需要比较好的GPU来跑才能快一点。
def train(epoch_num, batch_size, model, log_dir_name='log', lr_decay=False):
train_loader = paddle.batch(trainDataReader, batch_size=batch_size)
valid_loader = paddle.batch(trainDataReader, batch_size=batch_size)
log_dir = '/home/aistudio/'+log_dir_name+'/'+re.search(r'^.*_', model.full_name()).group()[:-1]
if os.path.exists(log_dir):
shutil.rmtree(log_dir)
train_loss_wrt = LogWriter(logdir=log_dir+'/train_loss')
train_acc_wrt = LogWriter(logdir=log_dir+'/train_acc')
val_loss_wrt = LogWriter(logdir=log_dir+'/val_loss')
val_acc_wrt = LogWriter(logdir=log_dir+'/val_acc')
if lr_decay == False:
opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameter_list=model.parameters())
else:
# opt=fluid.optimizer.Momentum(learning_rate=fluid.dygraph.ExponentialDecay(
# learning_rate=0.002,
# decay_steps=1000,
# decay_rate=0.1,
# staircase=True), momentum=0.9 , parameter_list=model.parameters())
opt=fluid.optimizer.Adam(learning_rate=fluid.dygraph.ExponentialDecay(
learning_rate=0.002,
decay_steps=1000,
decay_rate=0.1,
staircase=True), parameter_list=model.parameters())
# model_dict, _ = fluid.load_dygraph(model.full_name())
# model.load_dict(model_dict)
for epoch in range(epoch_num):
avg_loss_acc = np.zeros([6])
model.train()
for batch_id, data in enumerate(train_loader()):
xd = np.array([item[0] for item in data], dtype='float32').transpose(0, 3, 1, 2)
yd = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
img = fluid.dygraph.to_variable(xd)
label = fluid.dygraph.to_variable(yd)
logits = model(img)
pred = fluid.layers.softmax(logits)
loss = fluid.layers.softmax_with_cross_entropy(logits, label)
avg_loss = fluid.layers.mean(loss)
acc = fluid.layers.accuracy(input=pred, label=label)
avg_loss_acc[0] += avg_loss.numpy()[0]
avg_loss_acc[1] += acc.numpy()[0]
avg_loss_acc[2] += 1
if batch_id % 100==0:
print('epoch:', epoch, ', batch:', batch_id, ', train loss:', avg_loss.numpy(), ', train acc:', acc.numpy())
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
# break
model.eval()
for batch_id, data in enumerate(valid_loader()):
xd = np.array([item[0] for item in data], dtype='float32').transpose(0, 3, 1, 2)
yd = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
img = fluid.dygraph.to_variable(xd)
label = fluid.dygraph.to_variable(yd)
logits = model(img)
pred = fluid.layers.softmax(logits)
loss = fluid.layers.softmax_with_cross_entropy(logits, label)
avg_loss = fluid.layers.mean(loss)
acc = fluid.layers.accuracy(input=pred, label=label)
avg_loss_acc[3] += avg_loss.numpy()[0]
avg_loss_acc[4] += acc.numpy()[0]
avg_loss_acc[5] += 1
if batch_id % 100==0:
print('validation loss:', avg_loss.numpy(), ', validation acc:', acc.numpy())
fluid.save_dygraph(model.state_dict(), model.full_name())
avg_loss_acc[0:2] = avg_loss_acc[0:2] / avg_loss_acc[2]
avg_loss_acc[3:5] = avg_loss_acc[3:5] / avg_loss_acc[5]
avg_loss_acc = np.around(avg_loss_acc, decimals=4)
print('epoch:', epoch, 'train loss:', avg_loss_acc[0], ', train acc:', avg_loss_acc[1], ', validation loss:', avg_loss_acc[3], ', validation acc:', avg_loss_acc[4])
train_loss_wrt.add_scalar(tag='train_loss', step=epoch, value=avg_loss_acc[0])
train_acc_wrt.add_scalar(tag='train_acc', step=epoch, value=avg_loss_acc[1])
val_loss_wrt.add_scalar(tag='val_loss', step=epoch, value=avg_loss_acc[3])
val_acc_wrt.add_scalar(tag='val_acc', step=epoch, value=avg_loss_acc[4])
avg_loss_acc = 0.0
# 训练
with fluid.dygraph.guard(fluid.CUDAPlace(0)):
model = VGG_BN("VGG19_BN", num_classes=2, layer=19)
train(30, 50, model)
进行预测
预测完之后把预测结果的csv保存到本地。
def preprocess(img):
return cv2.resize(img,(300,300))
def evalReader(path="work/test"):
for name in os.listdir(path):
fullpath=os.path.join(path,name)
img=cv2.imread(fullpath)
img=preprocess(img)
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
assert img.shape==(300,300,3)
yield img,name[:-4]
def predict(model):
print('start predict ... ')
model_dict, _ = fluid.load_dygraph(model.full_name())
model.load_dict(model_dict)
model.eval()
df=[]
for item,name in evalReader():
item=np.array(item,dtype='float32').transpose(2,0,1).reshape(1,3,300,300)
# item2=np.array(item*255,dtype='int32').reshape(28,28)
# plt.imshow(item[0])
# plt.show()
img=fluid.dygraph.to_variable(item)
result = model(img)
# print(result)
# print("预测结果为",np.argmax(result.numpy()[0]))
df.append([name,np.argmax(result.numpy()[0])])
# time.sleep(0.5)
df=pd.DataFrame(df,columns=["id","label"])
df['id']=df['id'].apply(pd.to_numeric)
df=df.sort_values(by="id")
df.to_csv("result.csv")
if __name__ == '__main__':
# 创建模型
with fluid.dygraph.guard():
model = VGG_BN("VGG19_BN", num_classes=2, layer=19)
predict(model)
查看预测结果
自己也人工看了看预测结果表示还不错,就传到lintcode上去看看结果。最终的准确率大概在93%的样子。


