因为百度的AIStudio平台提供了免费的GPU算力,而且帮我配好了运行环境,只不过需要使用paddlepaddle这个框架,我就打算顺便在学习paddlepaddle的同时完成lintcode上面的刷题任务。
题目描述
题目链接
MNIST是计算机视觉领域的“hello world”数据集。 自1999年发布以来,这种手写图像的经典数据集已经成为基准分类算法的基础。 随着新的机器学习技术的出现,MNIST仍然是研究人员和学习者的可靠资源。
这个题目,您的目标是正确识别数以万计的手写图像数据集中的数字。
每一张图片,图片里面写了一个数字可能是0-9,然后需要设计算法判断出这个数字是0-9中哪一个数字。 我们鼓励您尝试不同的算法,以便第一手掌握哪些方法或者技术可行。
题目分析
对于手写数字识别,简单的网络即可完成这个任务,但是最让人难忘的是LeNet在这上面的表现,我这次用的就是LeNet看看最终究竟有多好的效果,优化器采用Aadm。
LeNet是最早的卷积神经网络之一。1998年,Yan LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如 图1 所示,这里展示的是作者论文中的LeNet-5模型:
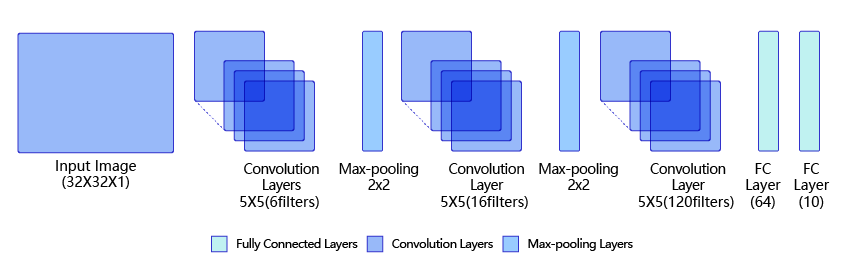
图1:LeNet模型网络结构示意图
第一模块:包含5×5的6通道卷积和2×2的池化。卷积提取图像中包含的特征模式(激活函数使用sigmoid),图像尺寸从32减小到28。经过池化层可以降低输出特征图对空间位置的敏感性,图像尺寸减到14。
第二模块:和第一模块尺寸相同,通道数由6增加为16。卷积操作使图像尺寸减小到10,经过池化后变成5。
第三模块:包含5×5的120通道卷积。卷积之后的图像尺寸减小到1,但是通道数增加为120。将经过第3次卷积提取到的特征图输入到全连接层。第一个全连接层的输出神经元的个数是64,第二个全连接层的输出神经元个数是分类标签的类别数,对于手写数字识别其大小是10。然后使用Softmax激活函数即可计算出每个类别的预测概率。
导入需要的包
主要是paddlepaddle、numpy等等科学计算的包,plt主要用于测试的时候显示图像。
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph import Conv2D, Pool2D, Linear, BatchNorm
import pandas as pd
import os
import random
import matplotlib.pyplot as plt
数据读取模块的编写
读取模块分为4个函数,一个是读训练数据,一个是读测试数据,一个是读全部有标签的数据,一个是读待预测的数据。
#数据读取模块
#训练数据
def trainDatareader(path='ml_problems_1_train.csv'):
df=pd.read_csv(path)
arr=np.array(df.values)
x=arr[:,1:]
x=x/255.0
y=arr[:,0]
for i in range(int(len(x)*0.9)):
yield np.array([x[i],y[i]])
#测试数据
def testDatareader(path='ml_problems_1_train.csv'):
df=pd.read_csv(path)
arr=np.array(df.values)
x=arr[:,1:]
x=x/255.0
y=arr[:,0]
for i in range(int(len(x)*0.9),len(x)):
yield np.array([x[i],y[i]])
#全部数据
def dataReader(path='ml_problems_1_train.csv'):
df=pd.read_csv(path)
arr=np.array(df.values)
x=arr[:,1:]
x=x/255.0
y=arr[:,0]
for i in range(len(x)):
yield np.array([x[i],y[i]])
#待预测数据
def evalReader(path="ml_problems_1_test.csv"):
df=pd.read_csv(path)
arr=np.array(df.values)
arr=arr/255.0
for i in range(len(arr)):
yield arr[i]
网络结构模块
# 定义 LeNet 网络结构
class LeNet(fluid.dygraph.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 创建卷积和池化层块,每个卷积层使用relu激活函数,后面跟着一个2x2的池化
self.conv1 = Conv2D(num_channels=1, num_filters=6, filter_size=5, act='sigmoid')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=6, num_filters=16, filter_size=5, act='sigmoid')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 创建第3个卷积层
self.conv3 = Conv2D(num_channels=16, num_filters=120, filter_size=4, act='sigmoid')
# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数
self.fc1 = Linear(input_dim=120, output_dim=64, act='relu')
self.fc2 = Linear(input_dim=64, output_dim=num_classes)
# 网络的前向计算过程
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = self.fc2(x)
return x
训练模块
一开始的batchsize是10后来改成50效果有所改善,而且小网络训练速度也比较快,可以多调几次参数看看。
# LeNet 识别手写数字 训练模块
# 定义训练过程
def train(model):
print('start training ... ')
# model_dict, _ = fluid.load_dygraph("LeNet")
# model.load_dict(model_dict)
model.train()
epoch_num =30
opt =fluid.optimizer.AdamOptimizer(learning_rate=0.0001, parameter_list=model.parameters())
# 使用Paddle自带的数据读取器
train_loader = paddle.batch(trainDatareader, batch_size=50)
valid_loader = paddle.batch(testDatareader, batch_size=50)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
# 调整输入数据形状和类型
x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)
#plt.imshow(x_data[0][0])
#plt.show()
y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
#print(y_data[0][0].shape)
# 将numpy.ndarray转化成Tensor
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 计算模型输出
#print(img)
logits = model(img)
#print(logits)
#print(logits)
# 计算损失函数
loss = fluid.layers.softmax_with_cross_entropy(logits, label)
avg_loss = fluid.layers.mean(loss)
if batch_id % 200 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
# 调整输入数据形状和类型
x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)
y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
# 将numpy.ndarray转化成Tensor
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 计算模型输出
logits = model(img)
pred = fluid.layers.softmax(logits)
# 计算损失函数
loss = fluid.layers.softmax_with_cross_entropy(logits, label)
#print(pred)
acc = fluid.layers.accuracy(pred, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# 保存模型参数
fluid.save_dygraph(model.state_dict(), 'LeNet')
if __name__ == '__main__':
# 创建模型 用GPU训练 没有配置好GPU环境的话把fluid.CUDAPlace(0)删掉就行
with fluid.dygraph.guard(fluid.CUDAPlace(0)):
model=LeNet(10)
#启动训练过程
train(model)
预测模块
预测并且将预测结果保存到csv文件中,到时候用excel打开删除第一列就可以了。
def predict(model):
print('start predict ... ')
model_dict, _ = fluid.load_dygraph("LeNet")
model.load_dict(model_dict)
model.eval()
df=[]
i=1
for item in evalReader():
item=np.array(item,dtype='float32').reshape(-1,1,28,28)
# item2=np.array(item*255,dtype='int32').reshape(28,28)
# plt.imshow(item2)
# plt.show()
img=fluid.dygraph.to_variable(item)
result = model(img)
# print(result)
# print("预测结果为",np.argmax(result.numpy()[0]))
df.append([i,np.argmax(result.numpy()[0])])
i+=1
# time.sleep(0.5)
df=pd.DataFrame(df,columns=["ImageId","Label"])
df.to_csv("results1.csv")
if __name__ == '__main__':
# 创建模型
with fluid.dygraph.guard():
model = LeNet(10)
#启动预测
predict(model)
看看成果
最终的准确率大概在97%左右,期间也尝试了很多其他的更先进的网络,譬如AlexNet但是大网络对于这种小尺度图片的效果也不一定会好,合适最好。
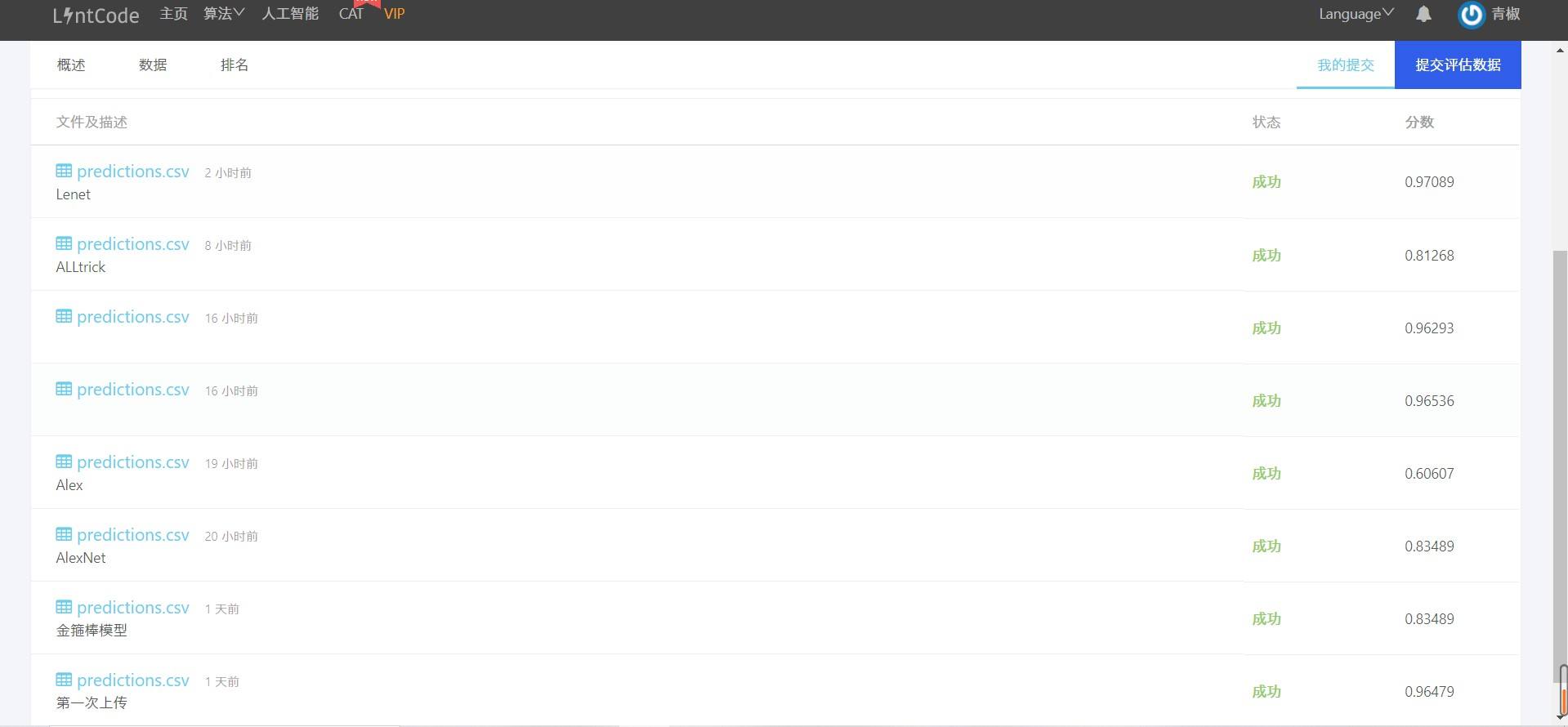
图2:预测准确率

